
本文是论文《Adversarial Image Registration with Application for MR and TRUS Image Fusion》的阅读笔记。
文章提出了一个基于GAN的对MRI和经直肠超声(TRUS)图像进行多模态配准的有监督网络模型AIR-Net,其中MRI被当作固定图像,而经直肠超声图像被当作浮动图像。
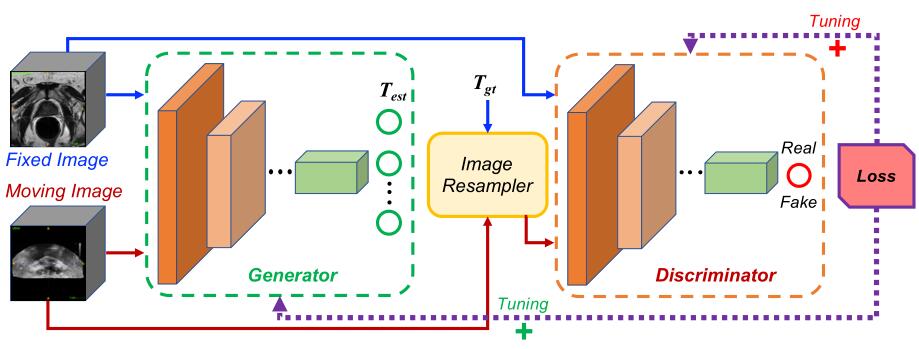
模型由生成器 $G$ 和判别器 $D$ 两部分组成,其中生成器直接估计一个从浮动图像到固定图像的转换参数 $T_{est}$;然后通过一个图像采样器分别使用估计的转换参数 $T_{est}$ 和真实(ground-truth)的转换参数 $T_{gt}$ 对浮动图像进行配准处理;并通过判别器来判断图像对是通过 $T_{est}$ 还是 $T_{gt}$ 来进行对齐的。
文章将三维图像看作是多通道的二维图像,
生成器的详细结构如下:
一个空洞卷积层(128通道, dilation rate为2)用来扩大感受野,两个卷积层(128通道,步长为2)用来降低分辨率,一个包含具有残差连接的三个卷积层的残差模块(128通道),一个卷积层(卷积核大小为$1\times1$,通道数为8)用来降低参数数量,两个全连接层用来得到最终的输出,第一个全连接层的输出为256维的,第二个全连接层的输出的维度和转换参数的个数相同(如果是三维刚性配准则有6个参数,如果是三维仿射配准则有12个参数)。以上卷积层如果没有特殊声明,卷积核大小都为$3\times3$,并且后面紧跟一个ReLU激活函数。
判别器的详细结构和生成器几乎相同,唯一不同的地方在于最后一个全连接层的输出维度为1,并且后面跟着一个Sigmoid激活函数。
判别器的损失为:
$$
\mathcal{L}(D)=-\mathbb{E}{T \sim p{g t}(T)}\left[D\left(I_{f}, I_{m}\right)\right]+\mathbb{E}{T \sim p{z}(T)}\left[D\left(I_{f}, T\left(I_{m}\right)\right]\right.
$$
其中 $ I_f $ 和 $ I_m$ 分别是固定图像和浮动图像,$\mathbb{E}{T \sim p{g t}(T)}\left[D\left(I_{f}, I_{m}\right)\right]$ 表示已经对齐的MR-TRUS的图像对的判别器损失的期望,而 $\mathbb{E}{T \sim p{z}(T)}[D(I_{f}, T(I_{m})]$ 表示随机对齐的图像对的判别器损失的期望。
生成器的损失为:
$$
\mathcal{L}(G)=\mathbb{E}{T \sim p{z}(T)}\left[1-D\left(I_{f}, T_{e s t}\left(T\left(I_{m}\right)\right)\right)+\alpha\left|T_{e s t}-T^{-1}\right|^{2}\right]
$$
其中 $||T_{eset}-T^{-1}||^2$ 是估计的转换和随机生成的转换之间的欧几里得距离。
在训练时采用了和WGAN(Wasserstein GAN)类似的方法,为了保证训练的稳定性,在每次更新判别器网络的参数即后,需要将其参数clip到某个范围内,clipping 参数值设置为0.1。并且没训练一次生成器网络,判别器网络会更新两次。


- 本文作者: 俎志昂
- 本文链接: zuzhiang.cn/2020/06/16/AIR-Net/
- 版权声明: 本博客所有文章除特别声明外,均采用 Apache License 2.0 许可协议。转载请注明出处!