
本文是论文《Weakly Supervised Adversarial Domain Adaptation for Semantic Segmentation in Urban Scenes》的阅读笔记。
在以往的语义分割由于像素级人工标注信息较难获得,并且可能并不准确,所以有些模型采用在生成的数据集上进行训练,然后将训练得到的模型应用在真实数据集上的方法来解决上述问题。但是这种方式的效果并不好。本文据此提出了弱监督的对抗域适应模型。该模型包括三部分,一是物体检测和语义分割模型(DS),用来检测物体并预测分割图;二是像素级的域分类器(PDC),它用来辨别图像特征来自哪个域;三是物体级的域分类器(ODC),它用来辨别物体来自哪个域并对物体类别进行预测。这三部分中,DS可以被看作生成器,PDC和ODC可以看作判别器。
语义分割可以看作是图像分割、物体定位和多物体识别的集合。本文针对的是全城市场景标记。
弱标签指的是图像级或物体级的标签。虽然生成数据集的出现解决了人工标注标签不足的问题,但是在生成图像和真实图像之间存在巨大的domain gap。本文要解决的就是跨模态的语义分割问题。
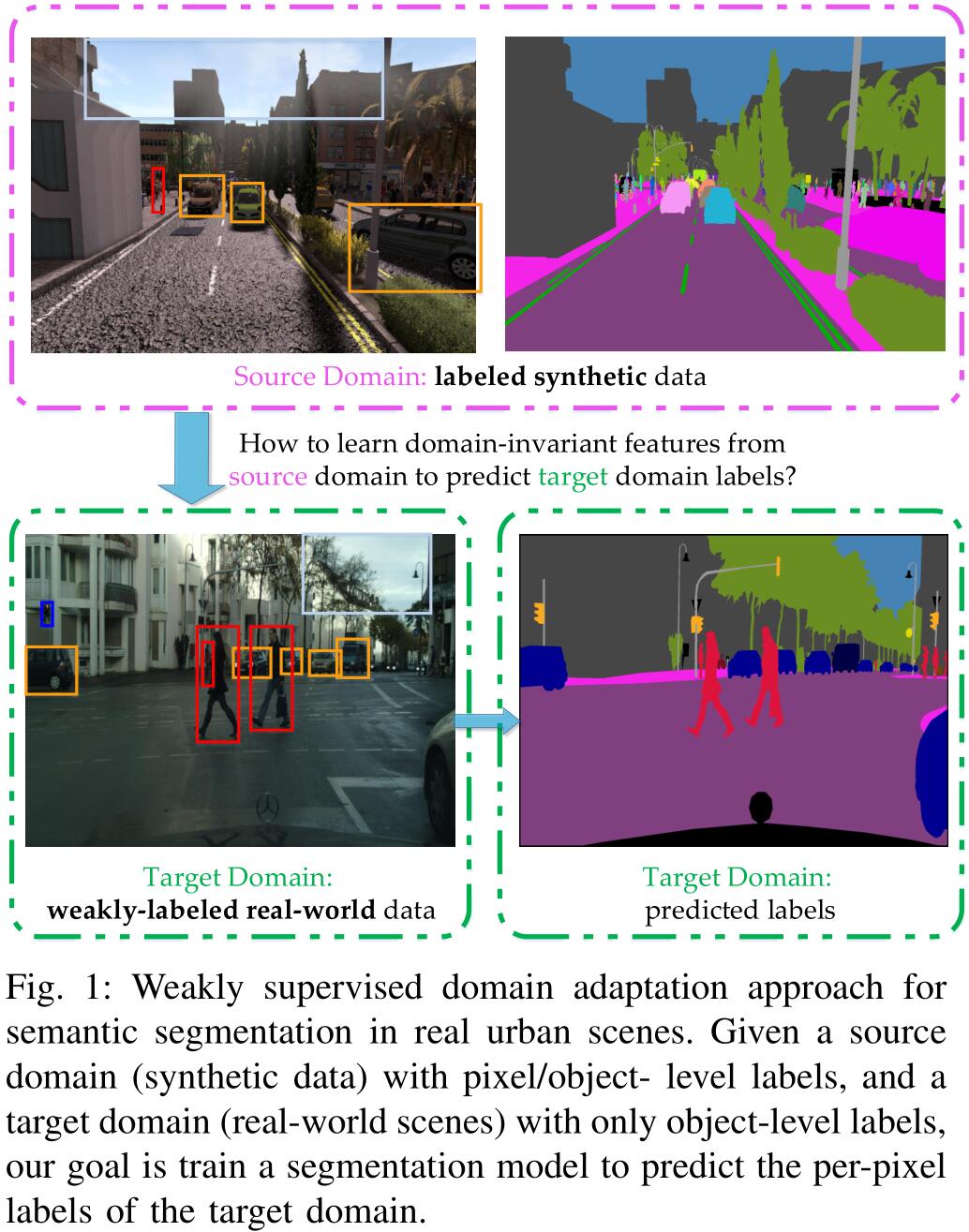
源域图像需要提供像素级和物体级的标签,而目标域图像只需要提供物体级的标签,目标是预测目标域图像每个像素的标签。
在物体检测和语义分割模型(DS)中,前者可以学习到物体级的特征,并定位物体的 bounding box,后者可以学习到局部特征,并实现像素级的分类。像素级的域分类器(PDC)的输入是分割网络的特征图,输出是源域和目标域图像的每个像素所属的域。物体级的域分类器(ODC)的输入是检测网络的物体特征,输出是物体的分类和域分类。
本文是第一篇用弱监督的方法做跨模态全城市场景标注的。
记号
$\mathcal{S}$:源域,即生成数据域
$I_{\mathcal{S}}$:源域图像
$A_{\mathcal{S}}^{pix}$:源域图像像素级标注
$A_\mathcal{S}^{obj}$:源域图像物体级标注
$\mathcal{T}$:目标域,即真实数据域
$I_{\mathcal{T}}$:源域图像
$A_\mathcal{T}^{obj}$:源域图像物体级标注
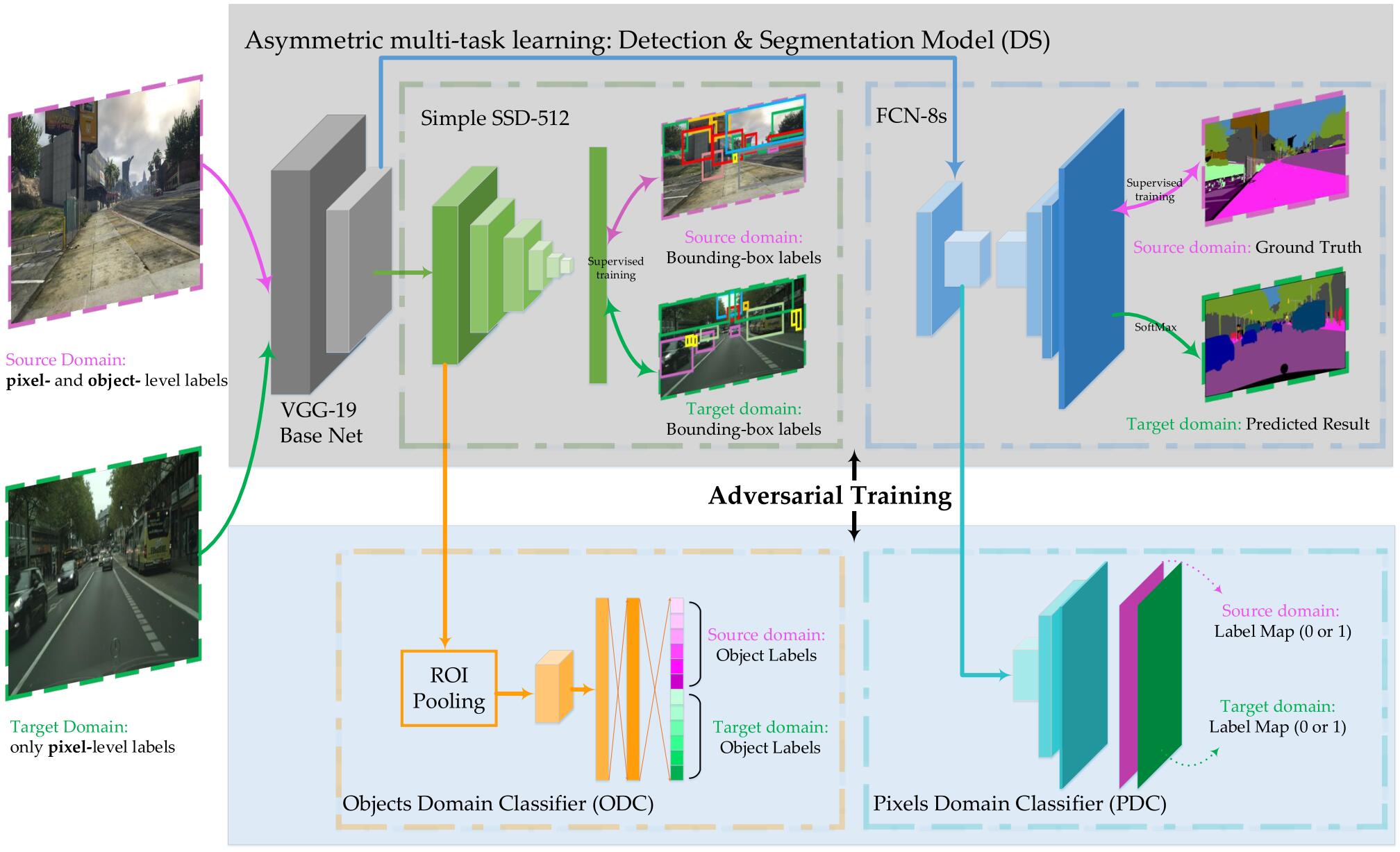
几乎所有的基于深度学习的语义分割是基于FCN的,但是基于FCN的方法聚焦在局部特征,而忽略了大尺度的结构特征。在训练时,源域图像参与整个模型的训练,而目标域图像只参与检测部分的训练。在测试阶段,测试图像只通过分割网络来预测每个像素的得分图。
在物体检测和语义分割模型(DS)中,将FCN-8和SSD-512结合成了一个模型,并且它们的前四个卷积层是共享的,被称作Base Net。SSD-512用作物体检测,FCN-8用作语义分割。
DS模型通过以下损失函数来进行训练:
$$
\begin{aligned}
\mathcal{L}{D S}=& \mathcal{L}{s e g}\left(I_{\mathcal{S}}, A_{\mathcal{S}}^{p i x}\right) \
&+\mathcal{L}{d e t}\left(I{\mathcal{S}}, A_{\mathcal{S}}^{o b j}\right)+L_{d e t}\left(I_{\mathcal{T}}, A_{\mathcal{T}}^{o b j}\right)
\end{aligned}
$$
其中,$\mathcal{L}{seg}(I_\mathcal{S},A_\mathcal{S}^{pix})$是二维交叉熵损失,$\mathcal{L}{det}(I_\mathcal{S},A_\mathcal{S}^{obj})$ 和$\mathcal{L}_{det}(I_\mathcal{T},A_\mathcal{T}^{obj})$ 是MultiBox目标损失。
PDC包括1个卷积层和2个反卷积层,PDC模型的损失如下:
$$
\begin{aligned}
\mathcal{L}{P D C}=&-\sum{O_{S}^{s e g} \in \mathcal{S}} \sum_{h \in H} \sum_{w \in W} \log \left(p\left(O_{S}^{P D C}\right)\right) \
&-\sum_{O_{\mathcal{T}}^{s e g} \in \mathcal{T}} \sum_{h \in H} \sum_{w \in W} \log \left(1-p\left(O_{\mathcal{T}}^{P D C}\right)\right)
\end{aligned}
$$
其中$O_\mathcal{S}^{PDC}$和$O_\mathcal{T}^{PDC}$是源域和目标域图像像素级的分割得分图,$p(\cdot)$是像素级的softmax操作。
PDC模型损失的逆为:
$$
\begin{aligned}
\mathcal{L}{P D C{i n v}}=&-\sum_{O_{S}^{s e g} \in \mathcal{S}} \sum_{h \in H} \sum_{w \in W} \log \left(1-p\left(O_{\mathcal{S}}^{P D C}\right)\right) \
&-\sum_{O_{\mathcal{T}}^{s e g} \in \mathcal{T}} \sum_{h \in H} \sum_{w \in W} \log \left(p\left(O_{\mathcal{T}}^{P D C}\right)\right)
\end{aligned}
$$
然而单独优化以上两个公式容易产生震荡,所以域融合损失为:
$$
\hat{\mathcal{L}}{P D C{i n v}}=\frac{1}{2}\left(\mathcal{L}{P D C}+\mathcal{L}{P D C_{i n v}}\right)
$$
最终的目标函数为:
$$
\begin{array}{c}
\min {\theta{P D C}} \mathcal{L}{P D C} \
\min _{\theta{D S}} \quad \mathcal{L}{D S}+\hat{\mathcal{L}}{P D C_{i n v}}
\end{array}
$$
其中$\theta_{DS}$和$\theta_PDC$分别为DS和PDC的参数,DS和PDC交替训练,在训练一者的时候另一者的参数保持不变。
为了从输入图像的特征图中获取精确的物体特征,通常选用ROI Pooling操作。ROI Pooling中的位置信息是通过ground truth来提供的。在ROI Pooling之后,具有相同大小的物体特征被输入到ODC中,在ODC中,每个标签都是采用one-hot编码的向量。
N维one-hot向量$Y_N(c)=[y_1,y_2,…,y_N]$定义为:
$$
y_{i}=\left{\begin{array}{ll}
1, & \text { if } i=c \
0, & \text { otherwise }
\end{array}\right.
$$
其中c为类别,源域中类别为c的物体,会生成一个one-hot向量$A_\mathcal{S}^c=Y_{2N}(c)$作为其标签。同理,目标域的标签为$A_\mathcal{T}^c=Y_{2N}(N+c)$,ODC的损失为:
$$
\begin{aligned}
\mathcal{L}{O D C}=& C E L\left(p\left(O{\mathcal{S}}^{O D C}\right), A_{\mathcal{S}}^{c}\right) \
&+C E L\left(p\left(O_{\mathcal{T}}^{O D C}\right), A_{\mathcal{T}}^{c}\right)
\end{aligned}
$$
其中$O_\mathcal{S}^{ODC}$和$O_\mathcal{T}^{ODC}$表示每个物品特征的得分向量,CEL函数是标准交叉熵损失。
同时ODC损失的逆被用来知道SSD-512学习域间不变性特征,源域和目标域标签的逆表示为$A_{\mathcal{S}{\text {inv}}}^{c}=Y{2 N}(N+c)$和$A_{\mathcal{T}{\text {inv}}}^{c}=Y{2 N}(c)$,ODC损失的逆为:
$$
\begin{aligned}
\mathcal{L}{O D C{i n v}}=& C E L\left(p\left(O_{S}^{O D C}\right), A_{\mathcal{S}{i n v}}^{c}\right) \
&+C E L\left(p\left(O{\mathcal{T}}^{O D C}\right), A_{\mathcal{T}{i n v}}^{c}\right)
\end{aligned}
$$
为了避免震荡,使用域融合目标函数:
$$
\hat{\mathcal{L}}{O D C_{i n v}}=\frac{1}{2}\left(\mathcal{L}{O D C}+\mathcal{L}{O D C_{i n v}}\right)
$$
整个模型(DS,PDC,ODC)的训练损失函数如下:
$$
\begin{array}{c}
\min {\theta{P D C}} \quad \mathcal{L}{P D C} \
\min _{\theta{O D C}} \quad \mathcal{L}{O D C} \
\min _{\theta{D S}} \quad \mathcal{L}{D S}+\hat{\mathcal{L}}{P D C_{i n v}}+\hat{\mathcal{L}}{O D C{i n v}}
\end{array}
$$
在训练模型的一个部分时,其他部分的参数保持不变。


- 本文作者: 俎志昂
- 本文链接: zuzhiang.cn/2020/06/06/WSAL/
- 版权声明: 本博客所有文章除特别声明外,均采用 Apache License 2.0 许可协议。转载请注明出处!