
本文是基于深度学习的单模态医学图像配准的综述,除了介绍配准任务、配准过程之外,还会从实际操作出发,以经典的VoxelMorph为例做详细介绍,重点讲了下自己踩过的坑。如果有什么讲的不清楚的地方欢迎大家留言讨论,如果有什么错误的地方,也恳请大家不吝赐教。
一、配准简介
配准问题简单来说就是让一张图像对齐到另一张图像,使得对齐后的图像尽可能相似。即,给定一个浮动图像(moving image)$I_M$和一张固定图像(fixed image)$I_F$。预测一个位移场$u$,进而得到形变场(deformation field)$\phi$,即从浮动图像到固定图像的映射,使得配准后的浮动图像(warped image)$I_W=I_M\circ\phi$和固定图像尽可能相似。其中像素位置$x$的变换可以表示为$\phi(x)=x+u(x)$。浮动图像又称源图像(source image),固定图像又称参考图像(reference image)、模板图像(template image),形变场又称流场(flow field)、配准场(registration field)、转换(transformation)。
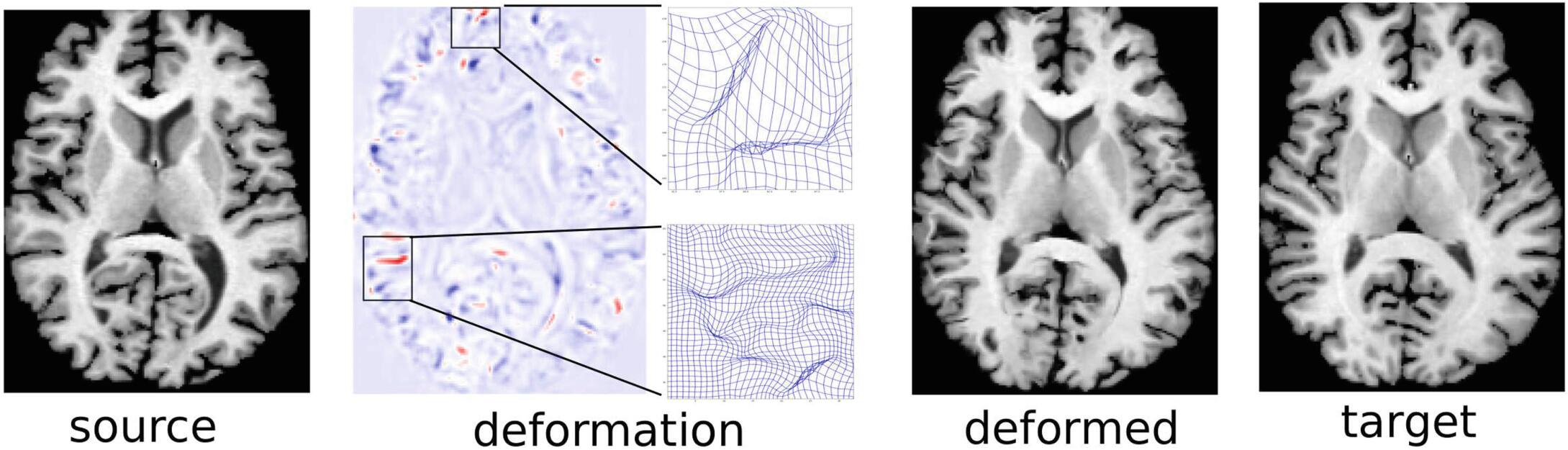
上图$^{[1]}$分别是源图像、形变场、配准后的源图像和目标图像,列出来让大家有个直观的认识。
二、配准问题分类
1. 线性配准和非线性配准
配准从不同的角度出发可以分为很多种,其中从图像变换的类型角度可以分为线性配准和非线性配准两种,线性配准包括刚体配准、仿射配准等,其中刚体配准是指只通过旋转和平移配准,而仿射配准则等于刚体配准+缩放。而本文所讲解的是针对非线性配准,在论文中通常称为“密度可变形配准(dense deformable registration)”,这个词可能我翻译的不是很准确。
2. 基于全分辨率图像的配准和基于patch的配准
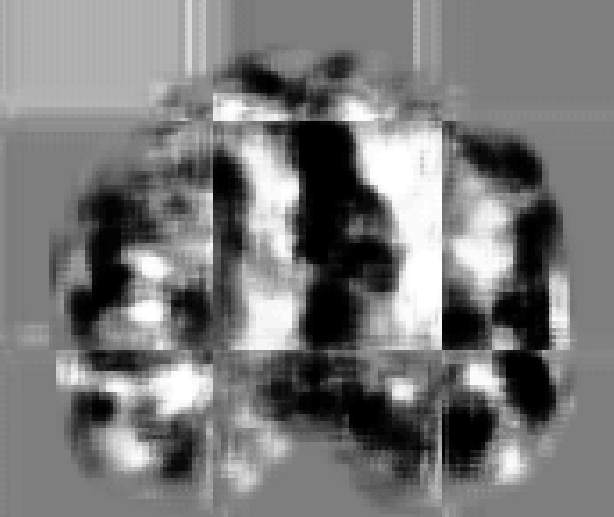
基于全分辨率的配准就是将整张图像进行处理,但是当图像较大时,显存可能会爆掉,当然也可以采用nnUNet$^{[2]}$中的方法,只保留必要的前景,将多余的黑色背景区域裁掉,以减小图像大小。或者每次取3D图像的一个2D切片进行配准。而基于patch的方法则是将图像裁剪成相同大小的块,每次对一小块进行处理,这样减少了显存的占用,但在将输出patch拼接成完整图像的时候拼凑感会十分明显(如上图所示),此时的处理方式通常是让输出patch之间有重叠,然后对重叠的部分取平均,这样会改善一点,但这种处理方法我没有实操过。输出patch中心的置信度比较高,而四周的较低。有些文章$^{[3]}$会采用输入patch大小大于输出patch大小的方法,从而更好的利用相邻体素的信息。
3. 传统的配准方法和基于学习的配准方法
1)传统的配准方法
根据配准算法依赖的方法不同,可以将配准分为传统的配准方法和基于学习的配准方法,其中传统的配准方法是指基于数学优化的方法,这种方法需要对每个图像进行迭代优化,因此耗费的时间较长,但通常效果比较好且稳定,据我导师说,医生一般都采用的是传统的方法。
2)基于学习的配准方法
而基于学习的配准方法指的就是通过神经网络训练的配准方法,该方法中参数是共享的,首先利用大量的数据来训练一个模型,然后用这个训练好的模型对一个新的图像进行配准。这种方式的优点在于虽然训练过程较为缓慢,但配准(测试)过程比传统方法快很多。缺点的话个人感觉一方面是用作训练的数据较少(特别是有监督的标签数据),另一方面感觉没传统方法稳定,可解释性也许也是一个问题。
i)有监督的基于学习的配准方法
基于学习的方法又可以分为有监督的配准方法和无监督的配准方法,有监督配准中的监督数据的获得主要有两种方式,一种是通过传统配准方法得到的形变场作为ground truth,另一种是对一张图像做随机模拟变形,将原始图像作为参考图像,变形图像作为浮动图像,模拟变形场作为监督信息 。有监督的配准的缺点很明显,以传统配准方法的形变场作为ground truth时,理论上模型的效果的上限不会超过传统的方法。另外就是可利用的高质量有监督数据较少,可以发现几乎没有手工标注的有监督数据(既耗时耗力又不现实)。
ii)无监督的基于学习的配准方法
而无监督的配准方法我认为是最近的研究的热点,因为配准本质上就是一个无监督的任务,只需要优化两张图像之间的相似度就可以了(更新一下,这种说法貌似有点问题,因为在测试时衡量的不是图像的相似性,而是label的相似性),不需要有监督信息也可以完成。最近也有很多利用GAN(生成对抗网络)来进行配准的无监督模型$^{[4]}$,这种模型的优点是不需要指定特定的图像相似度,这避免了由于数据集分布的不同,而导致固定的图像相似度衡量标准的通用性问题。但模型的缺点我觉得也很明显,就是GAN模型训练时一般很难收敛。PS:我在实现范敬凡老师的GAN配准模型$^{[3]}$时,就遇到了这种问题,有解决掉的朋友欢迎讨论。
三、配准网络框架
1. 配准网络框架

我心目中较为完美的配准网络框架是这样的:输入的浮动图像和固定图像在通道(channel)的维度进行拼接,先经过一个仿射配准网络进行仿射配准,然后再经过一个卷积神经网络(一般是类UNet的编码器-解码器网络)预测一个从浮动图像到固定图像的位移场,接着根据位移场得到一个采样网格,使用空间转换网络(Spatial transformer network,STN)$^{[5]}$利用该采样网格对浮动图像进行重采样,得到配准后的图像。
可以发现,上述框架比VoxelMorph$^{[6]}$的框架多了一个仿射配准模块,这是因为VoxelMorph在进行配准时通常是要求数据进行过预配准(通常是仿射配准),而没有经过预配准的图像通常配准效果较差,这可能是因为此时的位移较大,而模型对大位移的处理能力较差。为了解决大位移配准,也有论文提出了将多个配准模型级联$^{[7]}$来预测大变形的方法,这里不再展开。
2. 空间转换网络

上图是空间转换网络的示意图,本文中所提到的空间转换网络其实只包括上图中的网格生成器和采样器两部分。空间转换网络一开始提出时只是简单用作仿射变换等,后来采用了采样网格的方式使得它功能更加强大。对于大小为[W, H]的二维图像来说,其位移场大小为[W, H, 2];对于大小为[D, W, H]的三维图像来说,其位移场大小为[D, W, H, 3]。位移场表示每个体素/像素在各个方向(x,y,z轴)的位移。空间转换网络会根据位移场生成一个归一化后的采样网格,然后用该网络对图像进行采样,就得到了配准后的图像。
上图是形变场可视化后的图像,关于形变场的可视化,可以看我的文章。
3. 损失函数
配准网络的损失一般包括两部分,一是图像的相似性损失$\mathcal{L}{sim}(I_F,I_M\circ\phi)$,二是形变场的平滑正则项损失$\mathcal{L}{reg}(\phi)$。图像相似性损失有很多种,常见的有相关系数(Correlation Coefficient, CC)、归一化的相关系数(NCC)、互信息(Mutual Information, MI)、均方误差(MSE)等。当图像具有相似的灰度值分布时,通常采用MSE来评估灰度值的相似性;而在多模配准中,NCC和MI指标会更合适。
平滑正则项损失的作用是保证预测出的形变场的平滑性,避免形变场中的重叠。有些文章中将形变场描述为一个微分同胚(我不是很理解,以下表述可能不严谨,大家且粗略看看),即连续、可逆、可微的光滑映射,有些网络通过平滑正则项来实现,有些是通过循环一致性来实现$^{[8]}$。
四、VoxelMorph配准实例

上图是VoxelMorph的框架图,不是很熟悉VoxelMorph模型的同学还请参考我的笔记:VoxelMorph论文笔记。
1. 数据集及预处理
这里的数据集选用的是LPBA40数据集,在下载时注意需要翻墙,下载时从LPBA40 Subjects Native Space: MRI data and brain masks in native space和LPBA40 Subjects Delineation Space: MRI and label files in delineation space两个选项中下载得到的分别是native space和delineation space的图像数据,delineation space的数据集已经对齐到mni305空间(具体是什么我也不是很清楚)了,只需要做简单归一化效果就会很好,而native space的我配准的效果一直不好,所以建议用delineation space的图像。
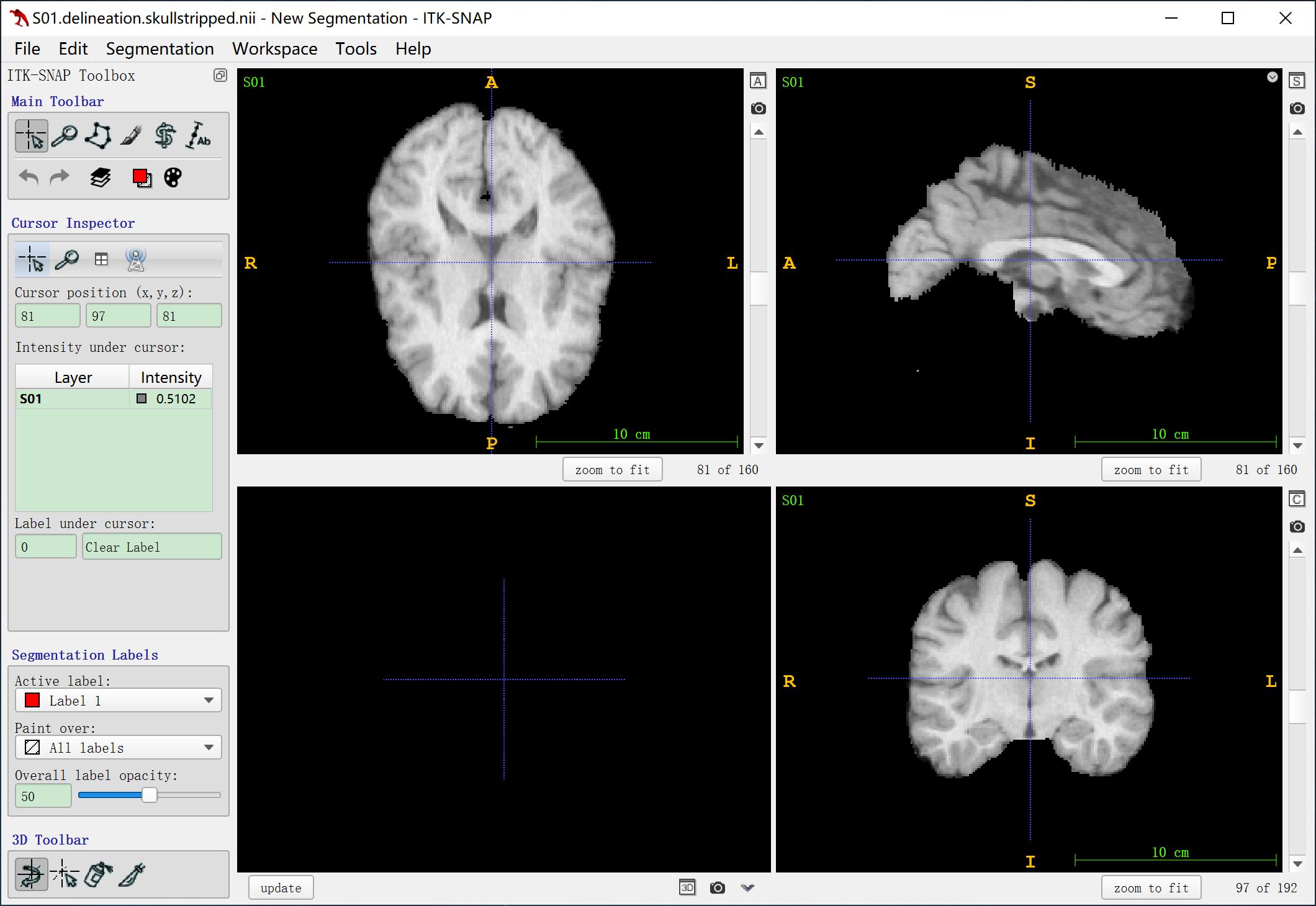
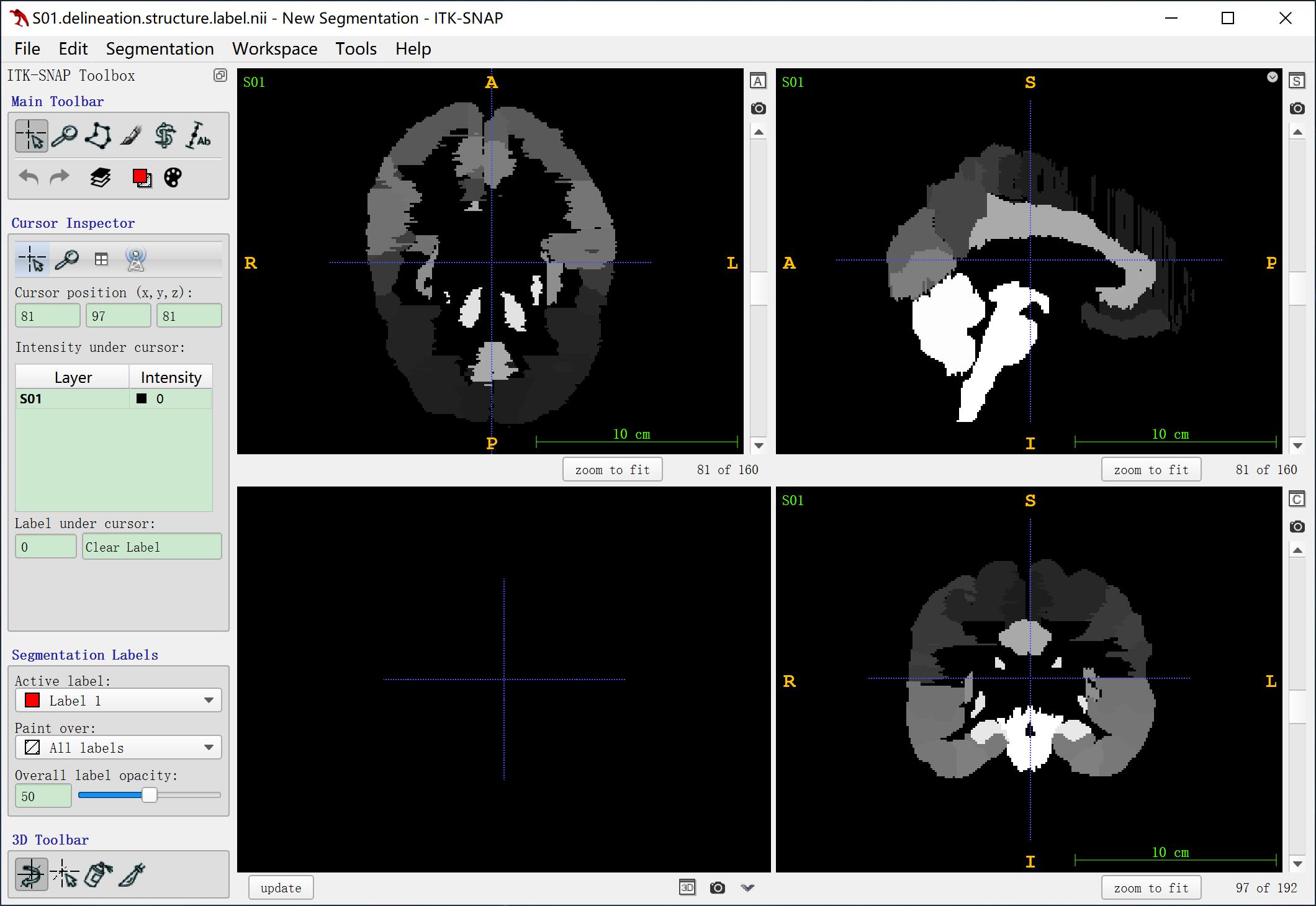
以上两图分别是LPBA40数据集中delineation space的图像和label。
关于LPBA40数据集的说明可以参考链接,提取码:8nio。其中label图有哪些类别,每个类别的编号和含义是什么里面都有说明。
在数据预处理时,我了解到的通常的流程是先用FreeSurfer将脑部的头骨去除,并进行仿射对齐(否则VoxelMorph的效果可能不好),然后将图像像素值归一化,然后将图像裁剪到合适的大小,同时将图像的体素间距统一一下,一般是统一到$1mm\times1mm\times1mm$。
图像归一化可以选择全局归一化和局部归一化,全局归一化即将每张图像减去所有图像灰度值的最小值,并除以所有图像灰度值的最大值 - 最小值;局部归一化就是将每张图像减去当前图像灰度值的最小值,并除以当前图像灰度值的最大值 - 最小值。对于delineation space的图像我做的是局部归一化,效果更好。全局归一化和局部归一化是我胡诌的两个名词。
需要裁剪到合适大小是因为VoxelMorph中的UNet网络中有4次下采样和4次上采样,所以要保证图像的[D, W, H]中的每个要连续除以4个2都是偶数。即如果图像的长为63,那么下采样一次变成31,上采样一次变成62,那么在跳跃连接的时候由于大小不同而无法直接拼接了。当然可以通过padding的方式(在四周填充黑色背景),或将图像resize到指定大小再拼接,但是感觉不够优雅,所以最好还是在一开始就将图像大小给确定好。
需要注意的是,在调整图像和label图大小的时候,label图的类别一般是固定的整数,如果通过插值的方法改变其大小的话可能会将其灰度值变成浮点数,即改变了标签的类别信息,这会在计算label图的DICE的时候造成麻烦。解决办法可以是尽量避免插值的方法改变图像大小,或在插值是使用最近邻插值。在经过FreeSurfer仿射配准后的图像和label图还有这种问题:图像和label无法同时做同样的仿射配准,即图像经过仿射配准了,但是label图没有。这里需要用FSL同时对图像和label图进行相同的变换,详情请见FSL同时对图像和label进行仿射对齐。不过LPBA40数据集的delineation space的图像我只做了像素值归一化和裁剪,没有使用FreeSurfer处理,所以没有该问题。
2. baseline
通常使用的一个baseline是ANTs软件包中的SyN配准算法,ANTs有直接安装版的,也有基于python的antspy,后者的配准速度会快很多,推荐后者。这里较为疑惑,不知道为什么会有如此大的速度差距。两者的安装和使用可以见我的ANTs笔记。
3. 训练
基于atlas的配准是指选定一张图像作为fixed图像,其他的作为moving图像;而非atlas的配准是每次随便选择两张图像做fixed和moving图像进行配准。基于atlas的配准在测试和训练时使用的是同一张固定图像,个人感觉基于atlas的配准方法容易过拟合,并且测试集使用的固定图像模型已经见过了,感觉有点奇怪。不过现在大多数论文采用的都是基于atlas的配准方法,本文也是。
LPBA40共40张3D脑部图像。训练时按照某些论文中的方法,随机挑选一张图像作为固定图像(我选择的是S01对应的图像),然后30张图像作为训练集(我选择的是S11-S40这30张),9张图像作为测试集(我选择的是S02-S10这9张)。
VoxelMorph的各种参数保持默认,即学习率为$1e^{-4}$,选用vm2版本,迭代训练1.5w次,选用NCC作为图像相似性损失,正则项的权重为1.0。(这里等我调好参数后再更新下,默认参数无法达到最优)
4. 测试
在用测试集对训练效果进行评价时主要有两块,一个是评估配准的效果,二是评估形变场的重叠程度。
配准效果的评估是对label图的每个标签类别计算DICE,从网上可以搜到两个DICE,一个是DICE系数,另一个是DICE损失,这里使用的是DICE系数,通常记为DSC(Dice similarity coefficient)。这里着重提出来的原因是我之前以为是对配准后的浮动图像和固定图像计算DSC,经过多方请教,应该是对配准后的label图计算DSC。DSC表达式如下:
$$
Dice(A,B)=2\cdot\frac{|A\cap B|}{|A|+|B|}
$$
用来评价形变场重叠程度的指标一般选择的是雅克比行列式中的负值个数(the total number of locations where Jacobian determinant $det(\nabla\phi^{-1}(x))$ are negative),其计算公式如下:
$$
\mathcal{N}:=\Sigma\delta(det(D\phi^{-1})<0)
$$
此外在一些论文中还会对配准后的地标(landmark)进行评价,即计算配准后对应地标之间的欧几里得距离,landmark可以简单的理解为图像中的关键点。
五、VoxelMorph代码
(2020.09.25更新)
基于Pytorch的VoxelMorph代码已经上传到github中,欢迎小伙伴们关注,如果能随手点个star那就感激不尽了~
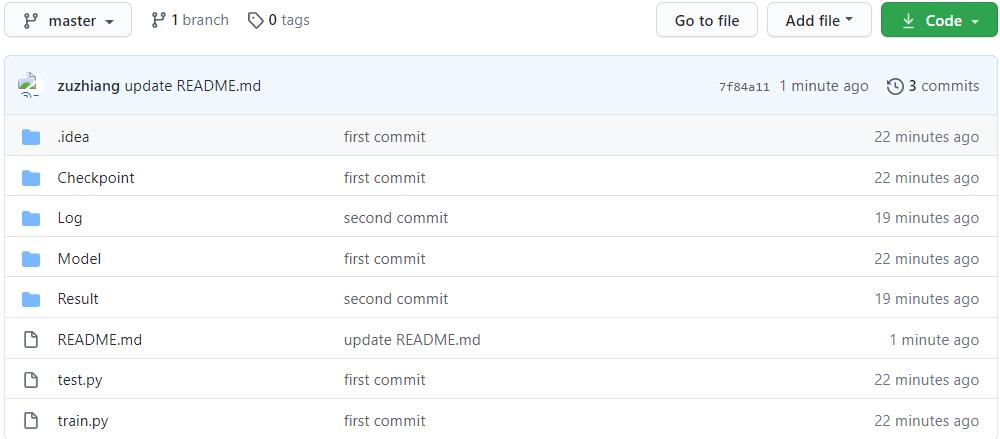
代码是在VoxelMorph官网源码的基础上做的修改(我发现最近源代码也更新了,变化还挺大的),修改后代码的目录结构如下:
Checkpoint:存放训练好的模型的文件夹;Log:存放日志文件的文件夹,记录各个参数下各种loss值的变化;Modelconfig.py:模型配置文件,用来指定学习率、训练次数、loss权重、batch size、保存间隔等,分为三部分,分别是公共参数、训练时参数和测试时参数;datagenerators.py:根据图像文件的路径提供数据,使用了torch.utils.data包来实现的;losses.py:各种损失函数的计算,包括形变场平滑性损失、MSE、DSC、NCC、CC、雅克比行列式中负值个数等;model.py:配准网络(U-Net)和空间变换网络(STN)的实现,并且将两者进行了模块化分离。
Result:存放训练和测试过程中产生的图像数据的文件夹;test.py:测试代码;train.py:训练代码。
我通过调参得到的最优参数(对于LPBA40数据集来说)如下:学习率为$4e^{-4}$,模型选用vm2版本,迭代训练1.5w次,选用NCC作为图像相似性损失,正则项的权重为4.0,batch size设为1。在测试集上测得的DSC值为0.6855077809012164,作为对比,ANTs包中的SyN算法配准的DSC值为0.6939350219828658。
已经训练好的模型也已经放在了项目的Model文件夹下,你可以通过下载我处理好的LPBA40数据集使用上面的参数得到同样的训练结果,数据集链接如下:https://pan.baidu.com/s/1RgjlNiTVq75-TI8p9q2bkw ,提取码:jyud 。当然,我个人觉得我对原始数据的处理足够简单,只做了裁剪和灰度值局部归一化,自己试着处理一下最好不过了。数据集目录结构如下:
train:训练图像数据,包括S11-S40共30个图像,只进行过裁剪到$160\times192\times160$大小,和局部归一化操作;test:测试图像数据,包括S02-S10共9个图像,只进行过裁剪到$160\times192\times160$大小,和局部归一化操作;label:标签数据,包括S01-S40共40个图像,只进行过裁剪到$160\times192\times160$大小的操作,无归一化;fixed.nii.gz:即S01图像,作为固定图像。
部分参考文献
[1] D.Y. Kuang, T. Schmah, “FAIM – A ConvNet Method for Unsupervised 3D Medical Image Registration”, CVPR, 2018.
[2] Z.W. Zhou, M.M.R. Siddiquee, N. Tajbakhsh, J.M. Liang, “UNet++: A Nested U-Net Architecture for Medical Image Segmentation”, CVPR, 2018.
[3] Fan J, Cao X, Wang Q, Yap PT, Shen D. Adversarial learning for mono- or multi-modal registration. Med Image Anal. 2019 Dec;58:101545. doi: 10.1016/j.media.2019.101545. Epub 2019 Aug 24. PMID: 31557633; PMCID: PMC7455790.
[4] J. F. Fan, X. H. Cao, Z. Xue, P. Yap, and D. G. Shen, “Adversarial similarity network for evaluating image
alignment in deep learning based registration,” vol. 11070, pp. 739–746, 2018.
[5] M. Jaderberg, K. Simonyan, A. Zisserman, and K. Kavukcuoglu, “Spatial transformer networks,” pp. 2017–2025, 2015.
[6] G. Balakrishnan, A. Zhao, M. R. Sabuncu, A. V. Dalca, and J. V. Guttag, “An unsupervised learning mod-
el for deformable medical image registration,” pp. 9252–9260, 2018.
[7] S.Y. Zhao, Y.Dong, E.Chang, and Y.Xu, “Recursive cascaded networks for unsupervised medical image registration,” pp. 10600–10610, 2019.
[8] Kuang D. (2019) Cycle-Consistent Training for Reducing Negative Jacobian Determinant in Deep Registration Networks. In: Burgos N., Gooya A., Svoboda D. (eds) Simulation and Synthesis in Medical Imaging. SASHIMI 2019. Lecture Notes in Computer Science, vol 11827. Springer, Cham. https://doi.org/10.1007/978-3-030-32778-1_13


- 本文作者: 俎志昂
- 本文链接: zuzhiang.cn/2020/09/15/registration/
- 版权声明: 本博客所有文章除特别声明外,均采用 Apache License 2.0 许可协议。转载请注明出处!