
本文是论文《3D Convolutional Neural Networks Image Registration Based on Efficient Supervised Learning from Artificial Deformations》的阅读笔记。
文章提出了一个使用人工位移向量场(DVF)进行训练的有监督非刚性图像配准网络RegNet,并提出了人工生成DVF的方法。
一、相关工作
使用传统的相似性标准的一个缺点是这些标准不是对所有图像都使用或者说最优的。在配准问题中,传统的监督信息主要有地标(landmark)信息和分割标签两种,但是使用他们作为金标准仍存在问题。比如在使用分割标签时,通常会采用Dice值或者MSD(平均表面距离)来作为评价指标,但是在Dice和图像所有体素的真实DVF之间没有直接的联系。在使用地标信息时,地标的数量不足以来为整个图像估计一个连续的金标准DVF。本模型通过增加捕获的范围,以在预测大形变场时达到更高的精度。
二、方法
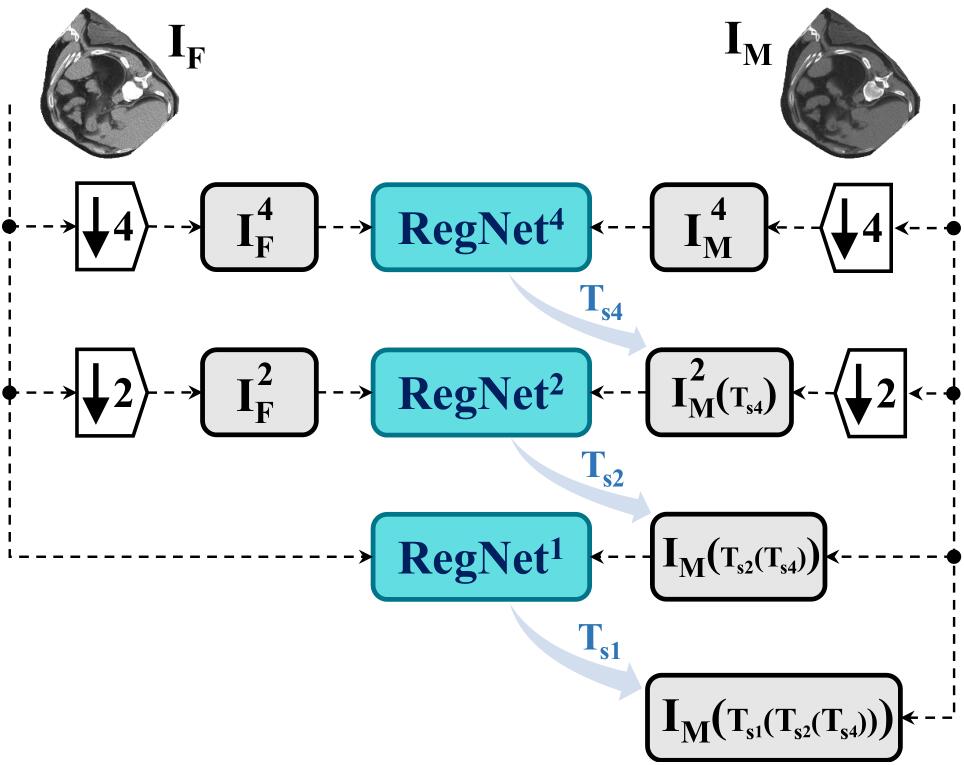
上图是RegNet的整体结构示意图。用$I_F$表示固定图像,$I_M$表示浮动图像。$RegNet^4$,$RegNet^2$,$RegNet^1$表示配准块,4和2表示下采样率是4和2。整个网络的输出可以表示为$T(x)=T_{s1}(T_{s2}(T_{s4}(x)))$。
1. 网络结构
网络结构有三种,前两种是基于patch的,而第三种是基于整幅图像的,采用的是UNet结构。最后一种结构可以看作是第一分辨率(resolution)($RegNet^4$)的候选者,其他的被看作是第二和第三分辨率($RegNet^2,RegNet^1$)的候选者。
除了UNet设计的网络结构的最后一层和基于patch的网络结构的最后三层,所有的卷积层都采用批正则化和ReLU激活函数。基于patch的网络结构的最后三层采用的是ELu激活函数。所有结构的最后一层都不使用批正则化也不使用激活函数。除了三线性上采样层使用的是固定的三线性卷积核,其他所有的卷积层使用的是Glorot均匀初始化器。
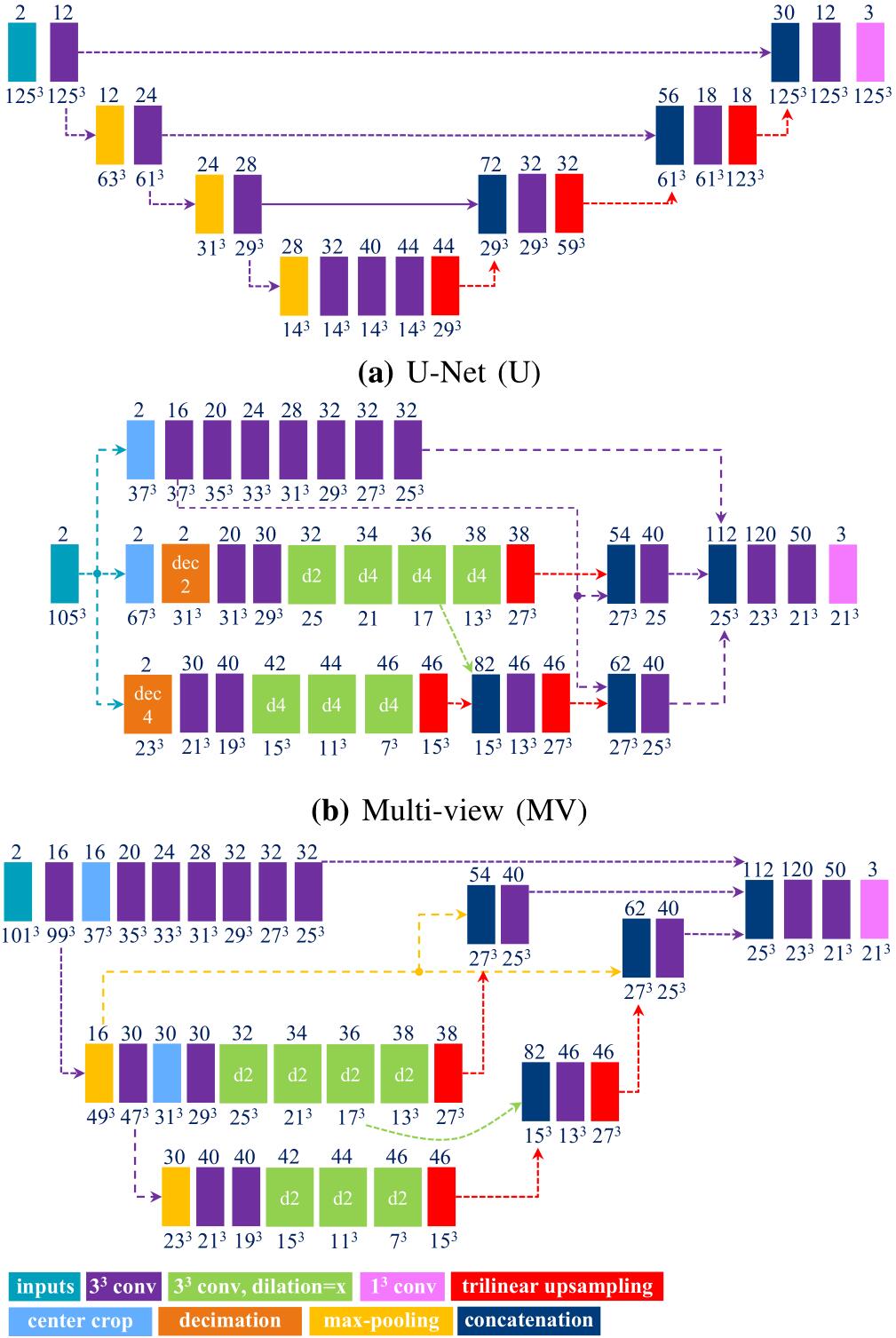
上图是以下三个网络的结构示意图。
UNet(U):UNet类型的网络结构的输入和输出大小均为$125\times125\times125$,该网络用作$RegNet^4$,即基于CNN的配准应用在了下采样率为4的下采样产生的图片上。
Multi-View(MV):使用具有固定B样条卷积核的卷积来抽取(decimation)生成不同尺寸的特征图。该模型的输入为大小为$105\times105\times105$的3D patch对,网络有三个分支:下采样率为4的下采样、下采样率为2的下采样和原始分辨率的处理。 为了节省内存,原始分辨率和下采样为2的被裁剪到$37\times37\times37$和$67\times67\times67$大小。使用具有固定的B样条卷积核的卷积来实现抽取。在下采样率为2的分支中,使用的是$7\times7\times7$大小的stretched B样条卷积核。在下采样率为4的分支中,采用的是$15\times15\times15$大小的stretched B样条卷积核。每个分支具有多个dilation为1或更高的卷积层。最后所有的分支的输出通过三个卷积层合并在一起。模型的输出是大小为$21\times21\times21$的位移场。
UNet-Advanced(Uadv):该模型是基于patch的,使用最大池化而不是提取(decimation)方法,整体的设计和UNet相类似,但是没有使用跳跃连接,而是使用几个卷积操作来实现连接。网络首先使用一个卷积操作来提取几个低级特征,输入和输出的大小分别为$101\times101\times101$和$21\times21\times21$。
2. 人工生成DVF和图像
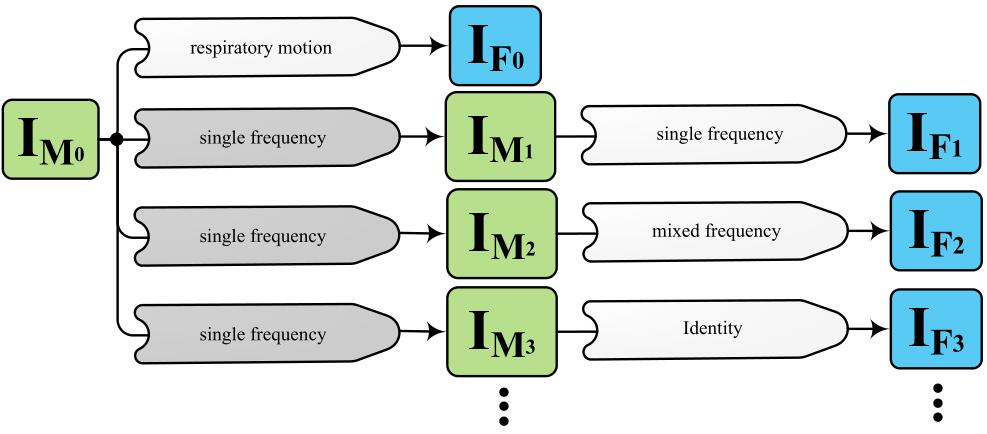
上图是人工合成DVF和图像的示意图。首先生成DVF,然后将DVF作用在浮动图像上生成初步的图像$I_F^{clean}$,然后通过人工灰度模型(artificial intensity model)来得到最终的固定图像$I_F$。对于人工的DVF主要有3种:
单频的:具有一个或多个仅具有一个空间频率局部位移。先生成一个控制点间距为s毫米的空B样条网格,随机给网格的控制点赋值,然后使用高斯核进行平滑,对B样条网格重采样得到DVF,然后将DVF线性正则化到$[-\theta,\theta]$的范围。
混频的:混合了两种不同的空间频率。先按照单频的过程生成一个单频的DVF,然后生成一个随机的二值mask,并和单频的DVF相乘。最后使用标准差为$\sigma_B$的高斯核进行平滑处理。与光滑填充区域相比,选择相对较小的$\sigma_B$以产生更高的空间频率。通过改变$\sigma_B$和s的值,来实现不同空间频率的混合。
呼吸运动:使用最大缩放因子为1.12来对横向平面的胸部进行膨胀,使用最大变形$\theta$对首尾方向的隔膜进行转换,使用单频方法进行随机转换。
恒定变换(identity):只包括恒等DVF。
3. 人工灰度模型:提出了两种灰度模型来应用在固定图像上
海绵(sponge)灰度模型:
$$
\boldsymbol{I}{\boldsymbol{F}}(x)=\boldsymbol{I}{\boldsymbol{F}}^{\operatorname{clean}}(x)\left[\boldsymbol{J}_{\boldsymbol{T}}(x)^{-1}\right.]
$$
其中$J$表示转换的雅克比行列式高斯噪声:在转换后的图像上加入了标准差为5的高斯噪声。
广泛配对生成(Extensive pair generation):如上部分图中灰色单频块所示。原始图像只使用一次来生成人工图像$I_{F0}$,然后在变形后的原始图像$I_{Mi}$的基础上进行变化,生成$(I_{M0},I_{F0}),(I_{M1},I_{F1}),(I_{M2},I_{F2}),…$。该模型的设置和单频相同,不同的是使用为3的标准差,这避免了在人工图像中噪声的累积。
总体来说,生成14种基本的人工DVF,5个单频的,4个混频的,4个呼吸运动的和1个恒定变换的。当空间频率提升时,雅克比直方图的分布将会更广,这表示图像的相关局部的改变增加。最大人工位移$\theta$在$RegNet^4,RegNet^2,RegNet^1$中分别是20,15和7。
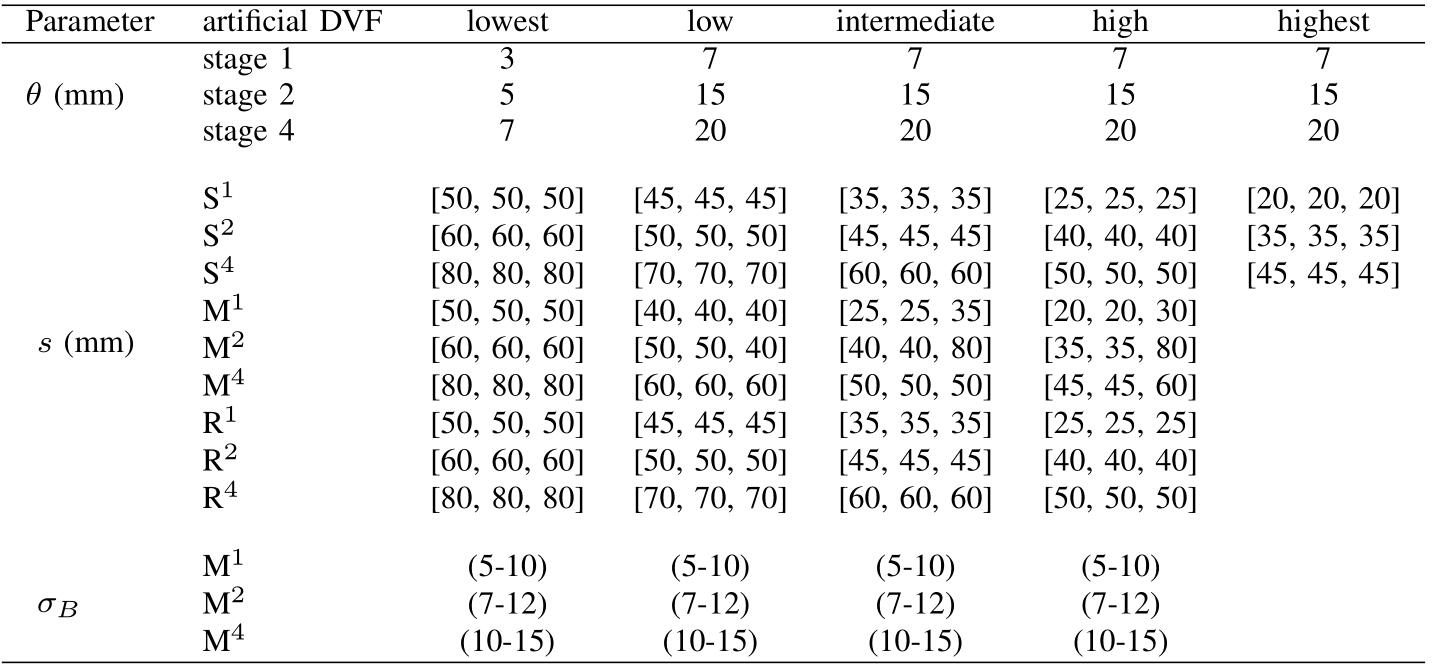
上图是在生成DVF的时候采取的各种参数,其中S/M/R分别表示单频、混频和呼吸运动。
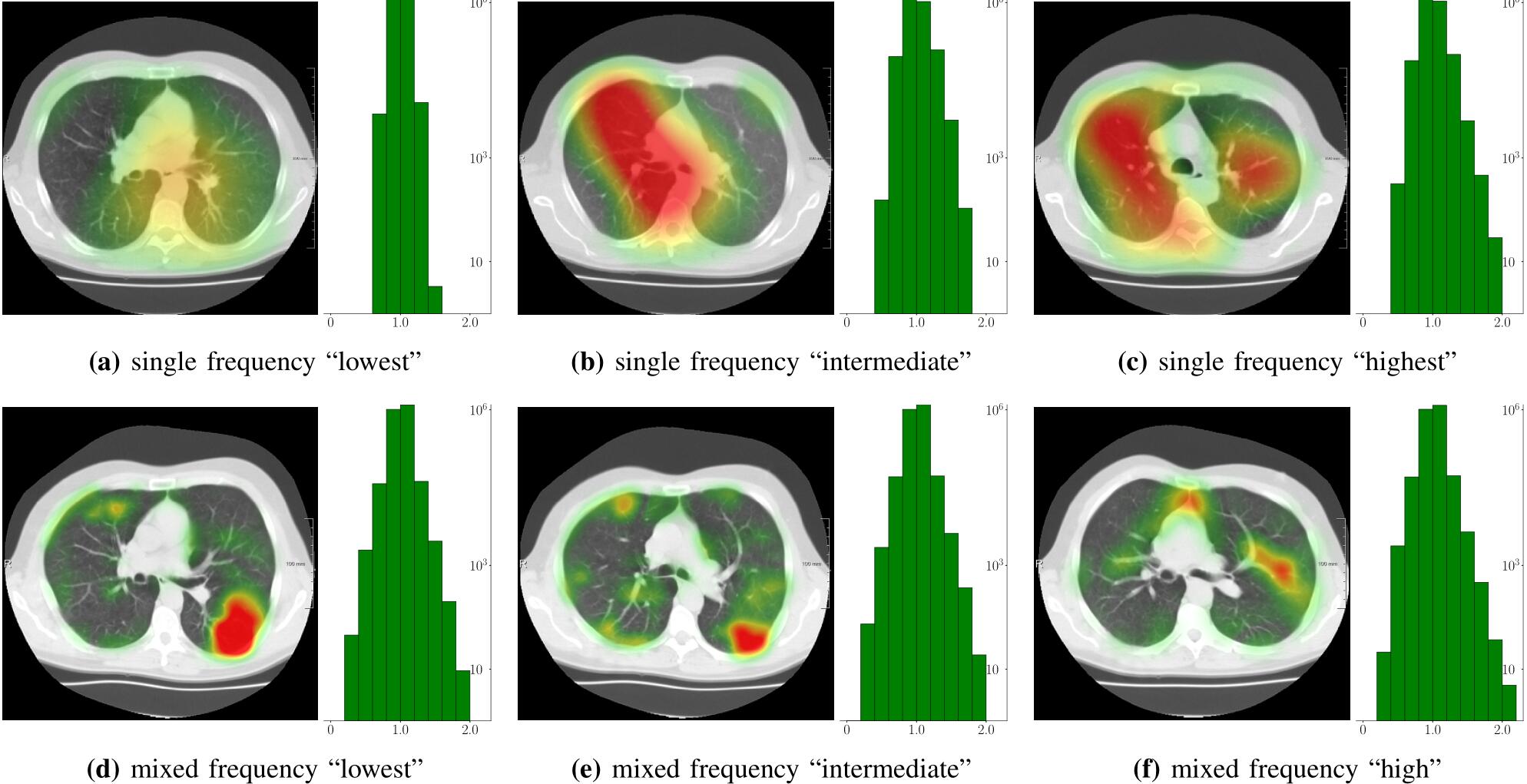
上图是采取上表中不同参数时的配准产生的DVF的热图,直方图是DVF的雅克比矩阵。
4. 优化
使用学习率为0.001的Adam优化器,损失函数包括两部分,一部分是Huber损失,用来最小化ground truth $T$和预测的DVF$T’$之间的距离,第二项是弯曲能(bending energy,BE)正则项,用来保证位移场的平滑。
$$
\mathcal{C}=\operatorname{Huber}\left(\boldsymbol{T}(\boldsymbol{x}), \boldsymbol{T}^{\prime}(\boldsymbol{x})\right)+\gamma \cdot \operatorname{BE}\left(\boldsymbol{T}^{\prime}(\boldsymbol{x})\right)
$$
其中,Huber损失为:
$$
\operatorname{Huber}\left(\boldsymbol{T}, \boldsymbol{T}^{\prime}\right)=\left{\begin{array}{ll}
\left(\boldsymbol{T}-\boldsymbol{T}^{\prime}\right)^{2}, & \left|\boldsymbol{T}-\boldsymbol{T}^{\prime}\right| \leq 1 \
\left|\boldsymbol{T}-\boldsymbol{T}^{\prime}\right|, & \left|\boldsymbol{T}-\boldsymbol{T}^{\prime}\right|>1
\end{array}\right.
$$
三、实验
1. 数据集
使用的数据集主要有:SPREAD、DIR-Lab-4DCT和DIR-Lab-COPD三个胸部CT图像数据集,每个数据集图像的大小、体素间距和地标个数还请看论文吧,这里就不赘述了。
在SPREAD数据集中训练集、验证集和测试集的个数包括10个病人、1个病人和8个病人的图像,每个病人有两张图像;DIR-Lab-COPD中训练集和验证集个数包括9个病人和1个病人的图像;DIR-Lab-4DCT全部用作测试集。
2. 评价指标
TRE:The target registration error,即配准后图像中对应地标的平均欧几里得距离,定义如下:
$$
\mathrm{TRE}=\frac{1}{n} \sum_{i=1}^{n}\left|\boldsymbol{T}^{\prime}\left(\boldsymbol{x}{F i}\right)+\boldsymbol{x}{F i}-\boldsymbol{x}{M i}\right|{2}
$$
其中,$x_F$和$x_M$是固定图像和浮动图像中对应的地标位置。
Jac:预测的DVF的雅克比行列式,作用是衡量图像的局部变化,当Jac值很大(Jac>>1)或很小(Jac<<1)或为负(Jac<0)时表示配准质量较差。
3. 其他设置
对于三个网络的每一个网络,在第一二三($RegNet^4,RegNet^2,RegNet^1$)阶段从每个原始图像生成70、42、28个人工图像对。
在训练阶段,基于patch的网络(MV和Uadv)的batch size为15,在阶段4、2、1,每个对图像的patch数为5、20和50。Uadv网络和MV网络的patch大小为$101^3$和$105^3$。训练有30个semi-epoch,在训练前有个数据增强操作,即为所有的patch添加高斯噪声。
选用的baseline为Elastix,其设置为:相似性度量为MI,优化器为自适应的随机梯度下降,采样B样条转换,分辨率个数为3,每个分辨率的迭代次数为500。
4. 实验
第一个实验中,只使用原分辨率的图像来进行训练和验证,不适用任何多阶段的pipeline。
在第二实验中,只使用最低分辨率的图像来进行训练和验证,不适用任何多阶段的pipeline。
在第三个实验中,使用下采样率为4和2的两阶段图像分辨率,实验表明,增加第二阶段可以提升RegNet的性能。
当再添加原始像素时,就构成三阶段的网络,此时在所有数据集上模型性能都有小幅度提升。
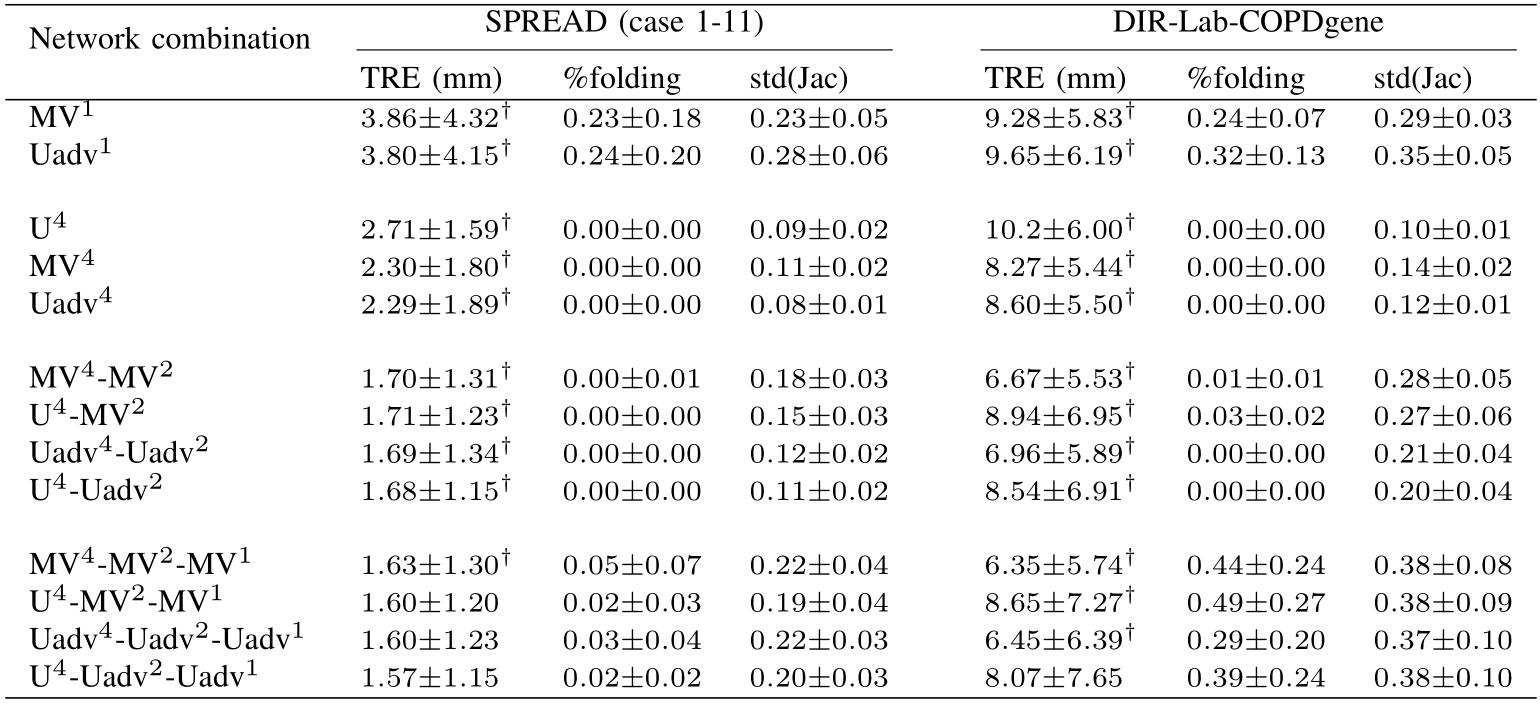
上图是在不同实验中在两个数据集的结果示意图。
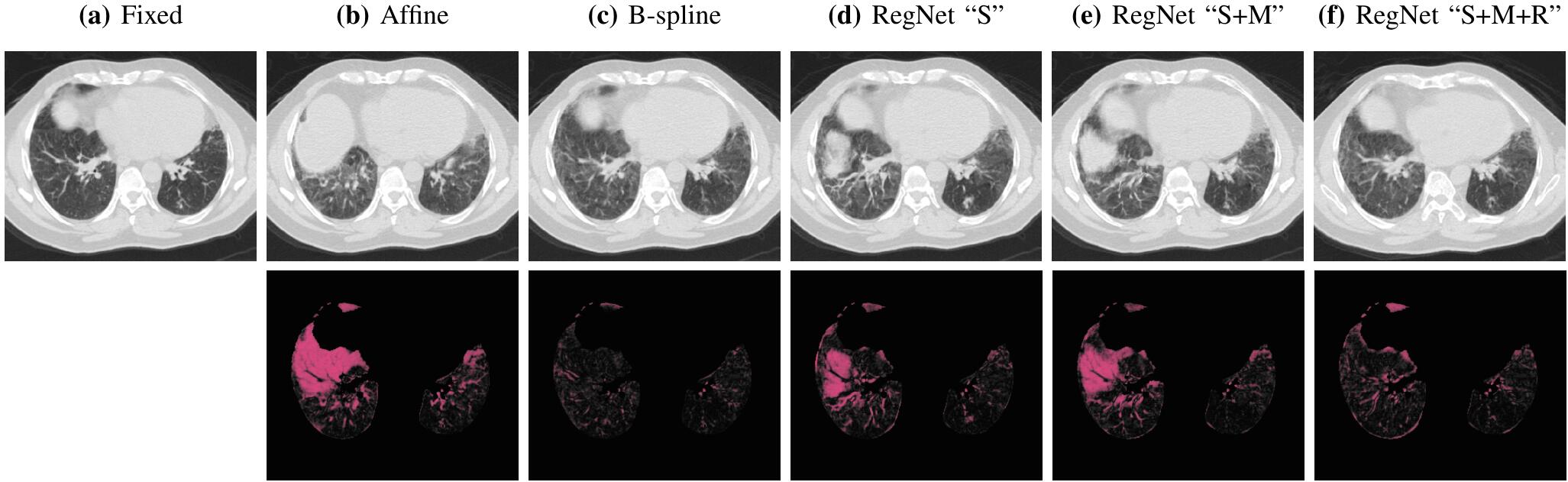
上图是在DIR-Lab-4DCT数据集上的配准结果示意图,下面一行是差异图。


- 本文作者: 俎志昂
- 本文链接: zuzhiang.cn/2020/08/16/RegNet-1/
- 版权声明: 本博客所有文章除特别声明外,均采用 Apache License 2.0 许可协议。转载请注明出处!