
本文是论文《Closing the Gap between Deep and Conventional Image Registration using Probabilistic Dense Displacement Networks》的阅读笔记,论文相关的代码见:PDD-Net。文章中的新鲜名次太多,看完也是稀里糊涂的。
一、概述
PDD-Net从名字就可以看出是“拼多多”公司提出的一个网络~好吧……并不是,PDD-Net是probabilistic dense displacement network的缩写。
相比于传统配准方法,基于学习的配准方法的劣势在于只能处理小的、低复杂度的变形。文章使用概率密度位移优化(probabilistic dense displacement optimisation)来解决该问题,概率密度位移优化已经在大变形配准任务上取得了很好的表现。文章设计了一个具有近似最小卷积(min-convolutions)和平均场(mean-field)的弱监督网络。该网络包括很少的可训练参数。
文章假设:病人间的大形变场很难通过没有使用复杂多阶段变形管道的深度连续回归网络来建模。文章的贡献有:更好的利用了通过引入了明确考虑到配准问题6D本性的可微分约束正则项来采样得到的概率密度位移的优势。因此,文章将卷积特征学习从空间变换的拟合中分离出来,使用用于正则化的平均场推理和用于计算标签间相容性的近似最小卷积。该模型是第一个结合了离散DLIR(Deep learnig based image registration)和可微分的平均场正则的方法。该模型具有较少的可训练参数,可以捕获大形变场,并且可以通过少量带有标签的图像进行训练并达到较高的准确度。此外还引入了一个非局部标签损失。
二、方法
$I_F,I_M$分别表示固定图像和浮动图像,$\varphi$表示形变场,$f$表示特征映射,将空间坐标定义为连续变量$x\in(-1,+1)^3$并且使用三线性插值来从离散网格中进行采样。$\varphi$通过$k\in|K|$个粗糙网格的控制点参数化。位移$d$的范围被离散位移空间所约束,线性间距为$\mathcal{L}=q\cdot{-1,-\frac{6}{7},-\frac{5}{7},…,+\frac{5}{7},+\frac{6}{7},+1}^3$,其中$q$是一个定义捕获范围的常量,$|\mathcal{L}|=3375$。网络模型可以预测一个位移概率$K\in\R^3\times\mathcal{L}\in\R^3$的6D张量,其中每个控制点中$\mathcal{L}$的4-6维的和是1。
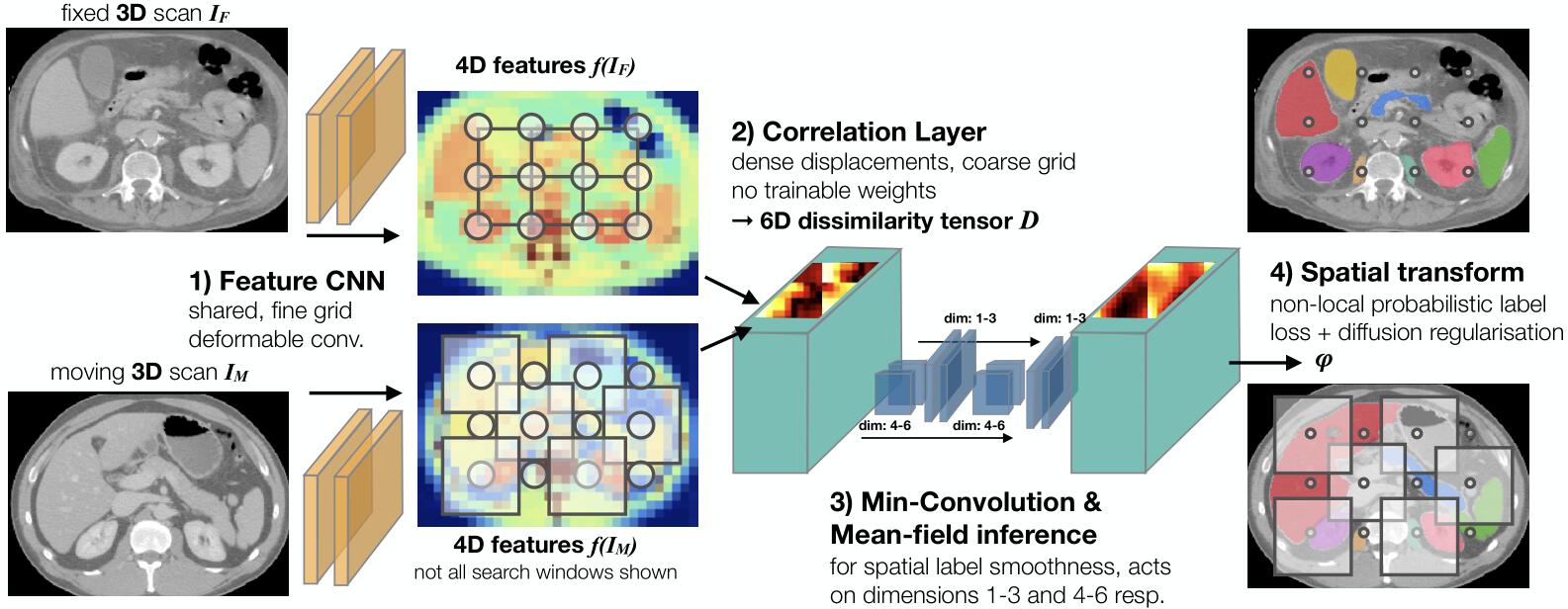
PDD-Net的网络结构如上图所示,主要有4个部分组成,其中变形卷积层(Feature CNN)可以提取固定图像和浮动图像的特征;相关层(Correlation Layer)为每个3D网格点计算一个密度位移空间,以生成一个6D的差异图;空间过滤器作用于维度4-6(Min-Convolution)和维度1-3(Mean-field inference)以促进平滑;使用softmax在维度4-6上获得的概率转换分布(Spatial transform)应用在非局部标签损失上,并且转换成一个3D位移场。这四个部分下面也会一一详细介绍。
1. 卷积特征学习网络
用来学习从输入灰度值到一个密度特征体(dense feature volume)的非线性映射。使用Obelisk方法,该方法包括一个3D可变形卷积和可训练的偏移量,然后是一个用于捕捉空间背景的$1\times1$的MLP。文章还在Obelisk层之前增加了一个$5\times5\times5$的卷积核来学习边缘特征。该网络有64个空间滤波器偏移量和总共120k个可训练参数,共享参数,用来根据固定图像和浮动图像产生$f(I_F)$和$f(I_M)$。
2. 密度位移差异相关层
给定从上一层得到的特征表示,该层的作用是为非线性变换的每个控制点指定一个向量$d$,以找到一个正则化的位移场以最大化固定图像和变形后的浮动图像之间的相似度。使用负的均方误差(MSE)来获得差异$\mathcal{D}(\mathbf{k}, \mathbf{d})=-\frac{1}{|c|} \sum_{c}\left(f_{c}\left(I_{F}\right){\mathbf{k}}-f{c}\left(I_{M}\right)_{\mathbf{k}+\mathbf{d}}\right)^{2}$的6D张量。位移场的捕获范围$q$被设为0.4。
3. 使用最小卷积和平均场推断的正则化
之前的DLIR通常通过损失项来保证形变场的空间平滑,PDD-Net将正则化约束作为网络结构的一部分。在马尔科夫随机场(MRF)配准中经常用基于位移平方差$\mathcal{R}\left(\mathbf{d}{i}, \mathbf{d}{j}\right)=\left|\mathbf{d}{i}-\mathbf{d}{j}\right|^{2}$的扩散型正则化作为位移的惩罚,即通过置信度传播(loopy belief propagation,LBP)进行优化。由于LBP需要多轮迭代来产生最优结果,所以不适用于作为展开的网络层。文章使用快速平均场推断(迭代两次)用于离散优化,它包括两个交替的过程:独立作用于空间控制点的标签兼容性转换,以及使用平均池化层(步长为1)实现的基于过滤器的消息传递。
4. 概率转换损失和有监督标签
可以进一步利用位移抽样的概率性质,并基于非局部均值加权来指定监督标签损失项,即首先使用在位移上计算的softmax将正则化部分(按$\alpha_6$缩放)的负输出转换为伪概率。接下来,在相同的空间位移位置对浮动图像分割的one-hot表示进行采样,并将这些向量乘以估计的概率,以计算分割的标签损失,即和ground truth的one-hot表示之间的MSE损失。通过概率估计值与位移标签的加权平均值乘以图像分辨率的三线性插值,得到连续值三维位移场。在位移场的所有3个空间梯度$\lambda \cdot\left(\left|\nabla \varphi_{1}\right|^{2}+\left|\nabla \varphi_{2}\right|^{2}+\left|\nabla \varphi_{3}\right|^{3}\right)$上使用扩散正则化惩罚,以实现平滑变换(雅可比标准差较低)和精确结构对准之间的平衡。
三、实验

使用的数据集是具有10个对比度增强的3D CT图像的VISCERAL3数据集,图像中9中解剖结构被人工标注出来,具体情况如上图所示。使用3折交叉验证。图像被重采样到各向同性的$1.5mm^3$的体素大小,图像尺寸为$233\times168\times286$,没有进行任何的预对齐。
选用传统配准方法NiftyReg和deeds作为baseline。并在数据集上训练弱监督的DLIR方法——Label-Reg,此时为了减少内存占用,将图像分辨率减少到$2.2mm$并且初始通道数减半改为16。
使用pytorch实现了FlowNet-C的3D扩展,该模型有一个Obelisk特征提取层、一个密度相关层和一个有$|\mathcal{L}|=3375$个输入通道的正则网络,有5个3D卷积层组成,每个卷积后有一个batch-norm和PReLU操作,输出是3D位移场。为了得到有意义的结果,在Obelisk层的输出后增加一个语义分割损失是有必要的。
其他设置为:$\lambda=1.5$,使用学习率为0.01的Adam优化器,迭代训练1500次。

由上图可知,PDD-Net比DLIR方法Label Reg和FlowNet-C的性能高出约15%,并缩小了与传统方法NiftyReg和deades的差距。消融也证明了PDD-Net有以下优点:1)使用学习的Obelisk特征与手工制作的自相似上下文(SSC)描述符;2)使用平均场推断;3)使用非局部标签损失。此外,pdd+inst还实施了快速实例级优化。
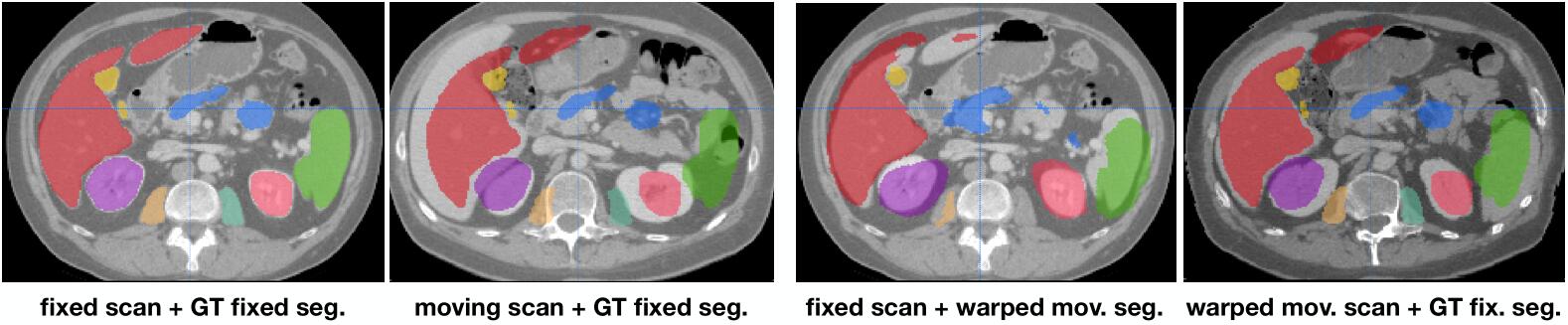
上图展示了配准后各个解剖结构分割标签的对齐情况。


- 本文作者: 俎志昂
- 本文链接: zuzhiang.cn/2020/08/06/PDD-Net/
- 版权声明: 本博客所有文章除特别声明外,均采用 Apache License 2.0 许可协议。转载请注明出处!