
本文是论文《Unsupervised End-to-end Learning for Deformable Medical Image Registration》的阅读笔记。该模型要比VoxelMorph更早一点,网络结构上两者非常类似,不同的是,本文的模型的配准网络采用的是FlowNet,而VoxelMorph采用的是UNet,两者结构是类似的,都是编码器-解码器结构,都有跳跃连接。此外,该模型在配准网络前面还加入了一个ROI分割网络,以将感兴趣的组织部分和背景分离开来。
一、概述
文章提出了一个无监督的端到端的深度医学图像配准模型,并且将ROI(感兴趣区域)分割mask引入到该模型中,以提升效果。文章的贡献主要有三个方面:
- 将传统的医学图像配准算法移植到了端到端的基于学习的医学图像配准中,同时保留了配准问题无监督的本性;
- 引入了ROI分割mask来减少背景的噪声并给出所要配准的器官的位置,这导致配准效果有了显著的提升;
- 配准的速度比传统算法快100倍。
下图是模型的整体示意图,但是ROI分割网络没有画出来,整体看来和VoxelMorph是很类似的。
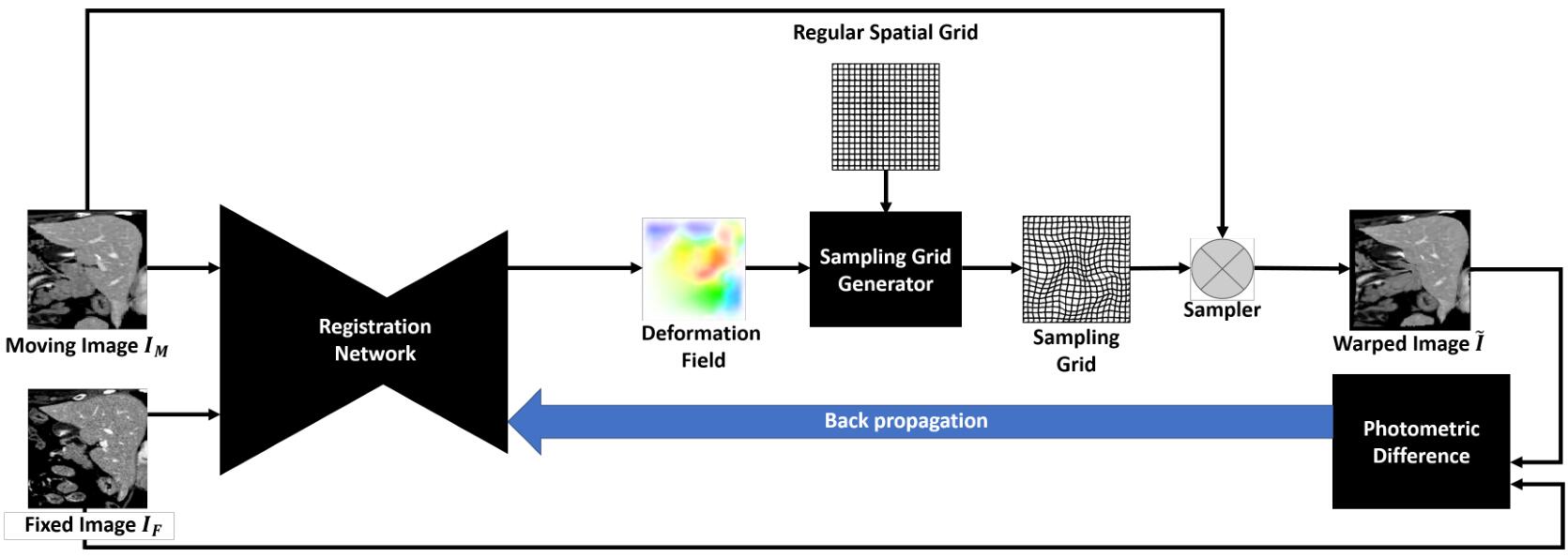
二、 传统的医学图像配准算法
传统的医学图像配准算法主要右损失函数(相似性度量)、多分辨率策略和坐标转换模型组成。损失函数用来衡量配准后两幅图像的相似程度,通常还会采用正则项来惩罚不希望的变形;多分辨率策略是一种已经被广泛采用的用来提升配准速度和优化稳定性的技术,它会生成不同分辨率的图像,并从粗糙到精细对其进行处理。其实类似于UNet结构的解码器部分每一层的输出的特征图,这些特征图是不同分辨率的;坐标转换模型是决定对图像做刚体变换、仿射变换、B样条变换还是更加复杂的变换。在坐标变换时,采用无参的变换模型是有必要的。无参的配准指在找到每个像素点单独的位移。
传统的方法有一个缺点就是对每张图像都要迭代更新,这就限制了配准的速度,同时也忽略了来自相同数据集图像的共同特性。
三、 方法
1. 定义:
- $I_M$:浮动图像
- $I_F$:固定图像
- $u$:形变场
- $\tilde{I}$:变形后的浮动图像,其定义如下
$$
\tilde{I}(x)=I_M(x+u(x))
$$
其中$x$表示像素位置。
形变场预测模型受到了FlowNet的启发,FlowNet用来解决光流估计问题,它的输入是两张图片,输出是一个用来使两张图像对齐的密集光流(形变场)。FlowNet的结构有点类似于UNet,由收缩路径和扩张路径组成,并且之间有跳跃连接。本文所提出的图像配准网络的详细结构如上图所示。
2. 相关工作
与本文密切相关的文章有FlowNet,STN(空间变换网络)、HNN(holistically-nested network)。
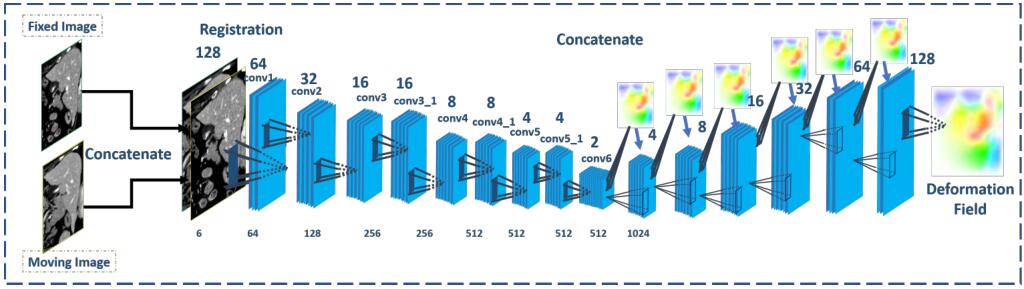
FlowNet本来是一个有监督的模型,为了解决该问题,可以将传统配准算法得到的配准结果当作ground truth。FlowNet的结构如下所示,图中忽略了跳跃连接,解码器每层上方的是不同分辨率的特征图,只有最后一层的特征图用作输出的形变场。
FlowNet的使用还是有些不协调,这是因为传统的算法是无监督,而神经网络的训练通常是有监督的。为了解决该问题,文章将STN插入到该模型中,用作无监督的学习。选择STN的原因有两个,一是它可以对图像进行变形,并且生成测光损失(photometric loss),二是它是通过双线性插值实现的,是完全可微的,可以进行反向传播。STN的工作原理是根据前面的网络(FlowNet)预测出来的形变场,从一个规整网格得到一个采样网格,然后用该采样网格对图像进行双线性插值的采样,得到变形后的图像。
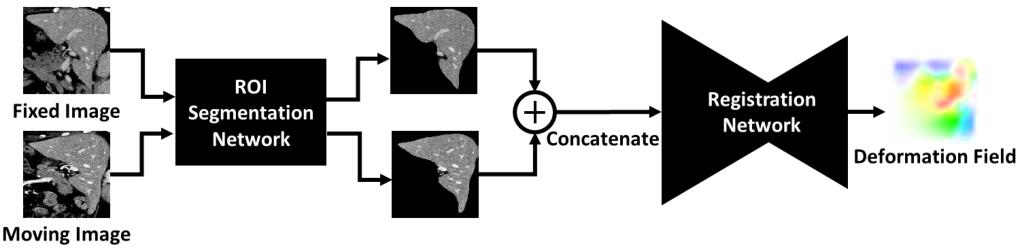
医学图像配准需要精确的分割mask以将配准的重点聚焦在特定ROI上,所以可以在图像配准网络的前面加上ROI分割网络,将要配准的组织分割出来,然后对其做基于分割mask的配准。这里选用的是HNN(holistically-nested net),ROI分割网络可以在给定足够的带有标签的训练数据的前提下,生成高质量的分割mask。HNN包括5个具有不同接收域大小的卷积阶段,每个阶段有一个side output,一个加权的融合层将所有的side outputs作为输入并得到一个融合了各个尺度信息的概率图。下图是ROI分割网络的示意图。
3. 损失函数
光度差损失(photometric difference loss):
$$
\mathcal{L}{\text {photometric }}^{s}=\sum{\mathbf{x} \in \Omega}\left|\tilde{I}^{s}(\mathbf{x})-I_{F}^{s}(\mathbf{x})\right|
$$
其中$\tilde{I}^{s}(\mathbf{x})=I_{M}^{s}\left(\mathbf{x}+\mathbf{u}^{\mathbf{s}}(\mathbf{x})\right)$是先将浮动图像resize到尺度$s$,然后根据形变场$u^s(x)$用STN对齐进行采样变形;$I_{F}^{s}(\mathbf{x})$是将固定图像resize到尺度$s$的结果;$\Omega$是二维图像空间。
形变场平滑损失:
该损失可以让预测出的形变场保持局部平滑的特性,文章一共提出了两种正则项,一个是$\mathcal{L}{smoothN}$,它是关于形变场梯度$\partial{u^s(x)}$的$L1$正则项,其表达式如下:
$$
\mathcal{L}{\text {smoothN}}^{s}=\sum_{\mathbf{x} \in \Omega}\left|\partial_{x} \mathbf{u}^{\mathbf{s}}(\mathbf{x})\right|+\left|\partial_{y} \mathbf{u}^{\mathbf{s}}(\mathbf{x})\right|
$$
其中$\partial{x},\partial{y}$是沿着两个方向的偏导。
$\mathcal{L}{smoothE}$是边缘感知项(edge-aware term)的$L1$加权惩罚项,其表达式如下:
$$
\mathcal{L}{\text {smooth} E}^{s}=\sum_{\mathbf{x} \in \Omega}\left|\partial_{x} \mathbf{u}^{\mathbf{s}}(\mathbf{x})\right| e^{-\left|\partial_{x} I_{F}^{s}(\mathbf{x})\right|}+\left|\partial_{y} \mathbf{u}^{\mathbf{s}}(\mathbf{x})\right| e^{-| \partial_{y} I_{F}^{s}(\mathbf{x})||}
$$
ROI分割网络HNN的总损失如下:
$$
\mathcal{L}{H N N}=\mathcal{L}{\text {side }}+\mathcal{L}{\text {fuse }}
$$
其中,$\mathcal{L}{side}$是每个side output的线性组合,$\mathcal{L}_{fuse}$表示融合的概率图的损失。
作者发现当单独使用光度差损失的时候,在某些特殊情况下会导致低质量的形变场,所以又加入了ROI边界重叠损失:
$$
\mathcal{L}{\text {overlap}}^{s}=\sum{\mathbf{x} \in \Omega}\left|\tilde{D}^{s}(\mathbf{x})-D_{F}^{s}(\mathbf{x})\right|
$$
其中$\tilde{D}^s(x)=D^s_M(x+u^s(x))$表示浮动图像resize到尺度$s$并通过STN变形后的ROI分割mask;$D^s_F(x)$是固定图像resize到尺度$s$后的ROI分割mask。
训练的总损失是以上失所有损失的加权和:
$$
\mathcal{L}=\eta \mathcal{L}{H N N}+\sum{s=1}^{7} \alpha_{s} \mathcal{L}{\text {photometric}}^{s}+\beta{s} \mathcal{L}{\text {smooth}}^{s}+\gamma{s} \mathcal{L}_{\text {overlap}}^{s}
$$
四、实验
作者在有ground truth和分割mask标注的两个数据集上做了实验,一个是肝脏CT图像,另一个是脑部MRI。作为对比的是传统配准方法,包括ANTs(advanced normalization tools)、Elastix和ITK(insight segmentation and registration toolkit)。同时还采用和FlowNet训练类似的有监督训练方式来作为baseline。
具体设置:采用$\beta_1=0.9,\beta_2=0.999$的Adam优化器,权重衰减为0.0005,batch size是32,HNN使用了预训练的5阶段的VGG来进行微调,FlowNet使用在Flying Chair数据集上训练的FlowNetSimple模型进行微调。在无监督训练时,学习率为$10^{-5}$,在开始10个epoch后,将学习率设为原来的一半,并在后面的7个epoch中保持不变。总损失函数中的$\eta,\alpha,\beta,\gamma$分别设为1,1,0.05和1。在有监督训练时,学习率为$1^{-4}$,经过4个epoch后,学习率衰减为$10^{-7}$,一共有10个epoch。
度量指标选择的是杰卡德系数(Jaccard coefficient)和Distance Between Corresponding Landmarks。前一个是用来衡量分割mask和ground truth之间的重叠度,后一个是用来衡量配准精细结构的能力。
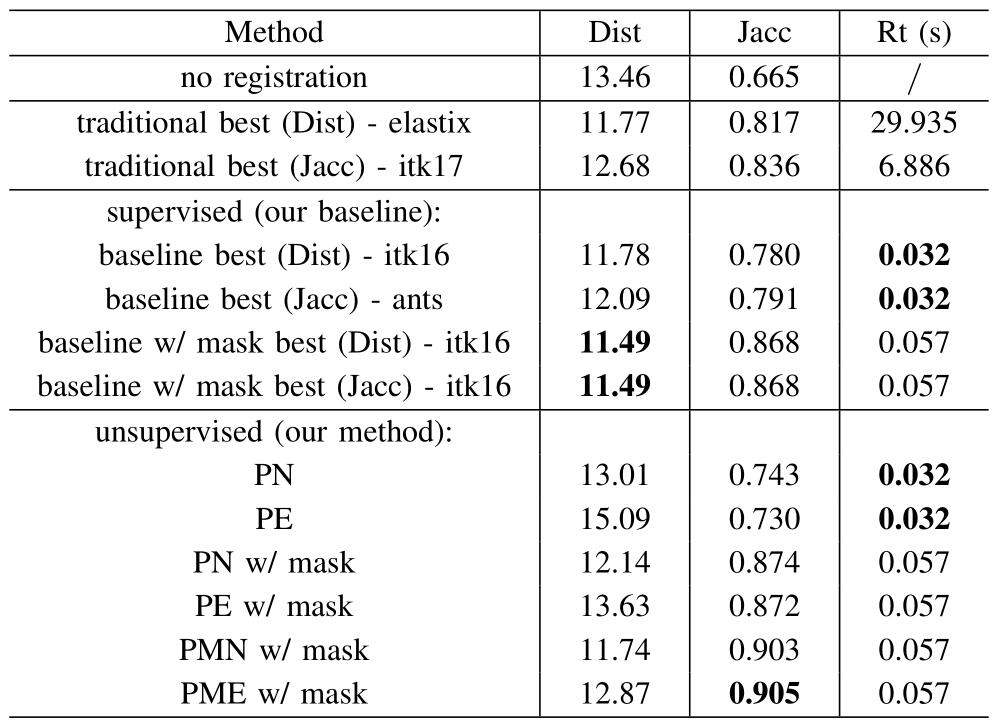
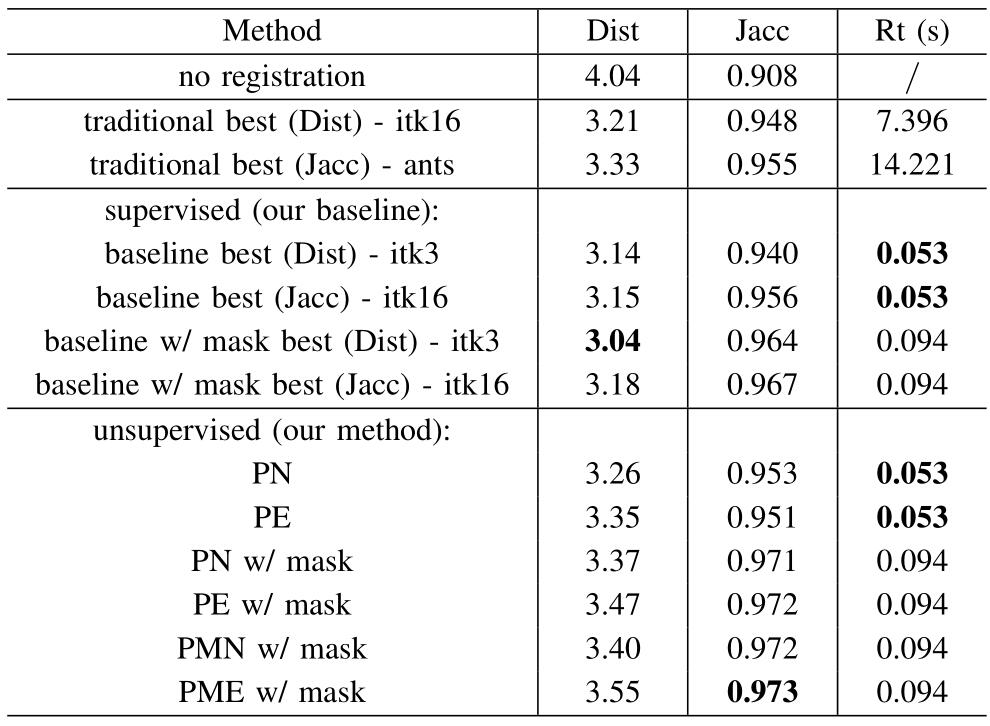
以下两图分别是肝脏和脑部数据配准的结果对比表,可以发现文章提出的有监督和无监督的方法会在两个评价指标上取得最优值,并且运行时间比传统方法要快很多。
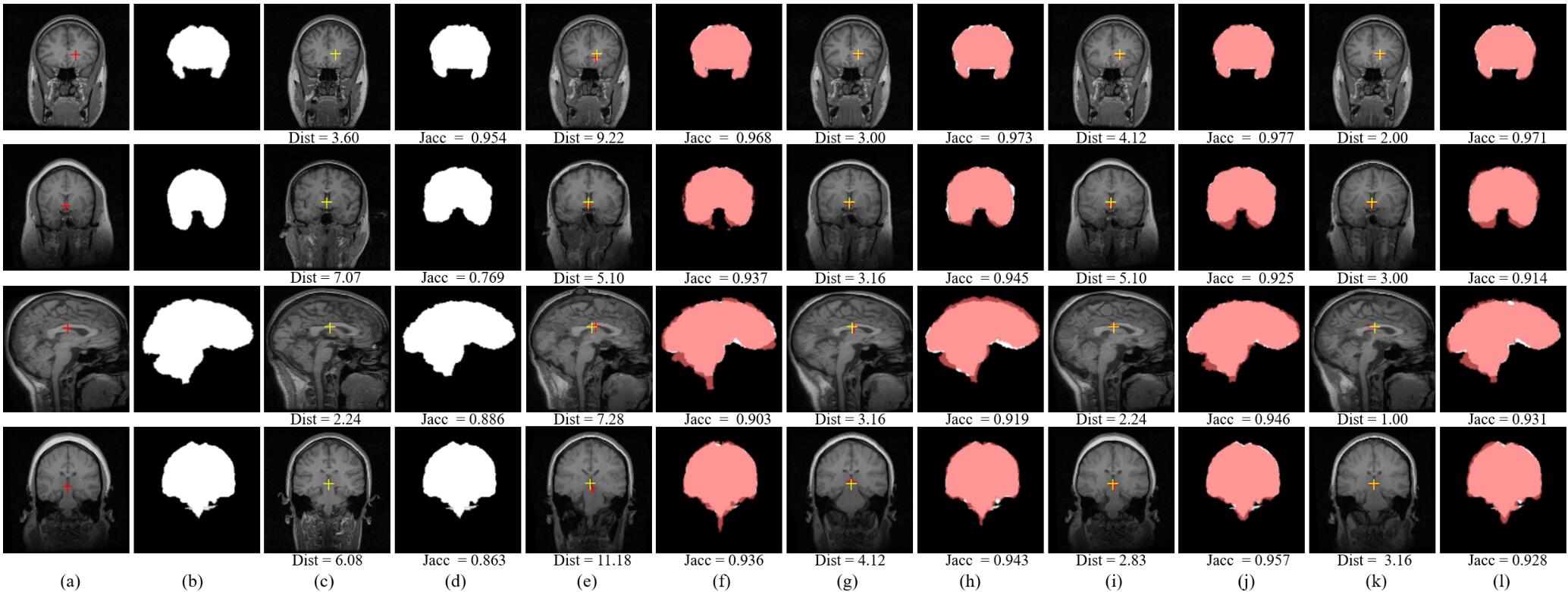
下图是脑部图像的配准结果,图片(a)-(l)分别表示:(a)浮动图像,(b)浮动图像的ground truth分割mask,(c)固定图像,(d)固定图像的ground truth分割mask,(e)、(g)、(i)、(k)分别表示浮动图像经过最优的传统配准方法(itk16)、最优的有监督baseline、最优有监督baseline w/ mask方法和最优的无监督方法变形得到的结果。(f)、(h)、(j)、(l)中的白色部分是对应图像的ground truth分割mask,红色部分是对应图像的根据预测形变场变形后的ground truth分割mask。


- 本文作者: 俎志昂
- 本文链接: zuzhiang.cn/2020/07/15/UnsupervisedEnd-to-endLearningForDeformableMedicalImageRegistration/
- 版权声明: 本博客所有文章除特别声明外,均采用 Apache License 2.0 许可协议。转载请注明出处!